
AI大模型破局:内存压缩与高速互连新战场
问题意识
Optimizing Foundational Models: Hardware-Accelerated Memory Compression & Interconnects
Nilesh Shah ZeroPoint Technologies
Rohit Mittal Auradine
背景介绍
随着生成式AI的爆发,大语言模型(LLM)正以前所未有的速度重塑着技术格局。然而,在这场AI浪潮的背后,我们正面临着严峻的挑战:日益增长的模型规模对内存容量和数据传输速度提出了“永不满足”的需求。传统的AI基础设施是否已触及性能天花板?我们该如何突破“内存墙”和“互连瓶颈”,才能真正释放AI的全部潜力?本文将深入探讨两大前沿技术:ZeroPoint Technologies的硬件加速内存压缩,以及Auradine倡导的开放高速互连标准。我们将揭示这些创新如何从根本上优化AI推理性能、降低TCO,并重新定义AI时代的算力基础设施。
阅读收获
- 洞察AI推理瓶颈: 深入理解LLM推理中“内存受限”的本质,以及为何内存容量和带宽成为当前AI性能提升的关键制约。
- 掌握硬件压缩利器: 学习ZeroPoint的无损缓存行压缩技术如何以纳秒级延迟,透明地倍增有效内存容量和带宽,尤其在KV缓存优化上的巨大潜力。
- 理解机架级互连价值: 认识到AI竞争已从“芯片之争”转向“系统和互连之争”,以及交换矩阵式网络和UALink等开放标准如何驱动机架规模AI的性能飞跃。
- 前瞻AI基础设施趋势: 把握AI基础设施从专有方案走向开放标准的演进方向,为未来AI系统设计和选型提供决策依据。
开放性问题
- ZeroPoint的硬件无损内存压缩技术,在实际大规模AI部署中,除了性能提升,还可能带来哪些新的系统设计挑战或安全考量?
- Auradine倡导的UALink等开放互连标准,在打破NVIDIA InfiniBand等专有生态壁垒的过程中,将面临哪些技术和商业上的主要阻力?其普及的关键因素会是什么?
- 随着AI计算单元从“芯片”转向“机架”,您认为未来的AI数据中心架构将如何进一步演进?边缘AI和混合云策略将如何与这种趋势结合?
👉 划线高亮 观点批注
Main

1. ZeroPoint Technologies
公司定位: 硬件加速内存优化解决方案提供商。
这家公司专注于解决“内存墙”(Memory Wall)和“内存容量瓶颈”问题,这在运行像基础模型这样极度消耗内存的AI工作负载时尤为突出。
-
核心技术: 他们的核心产品是硬件IP(知识产权)模块,这些模块被集成到CPU、SoC(片上系统)或CXL(Compute Express Link)控制器中。
-
主要功能: 该技术能对内存中的数据进行实时的、超低延迟的透明压缩和解压缩。这意味着系统可以(例如)在DRAM中存储2倍甚至更多的数据,而应用程序本身却毫不知情(因此称为“透明”)。
-
关键产品(如DenseMem™): 专为CXL内存扩展设备设计,可以使CXL连接的内存容量(即“内存扩展”)增加2到3倍,同时保持极低的访问延迟。
-
与PPT主题的关联: 正如PPT标题“硬件加速的内存压缩”所言,ZeroPoint Technologies提供的正是这项关键技术。通过在硬件层面压缩内存,AI服务器可以用更低的成本(更少的DRAM芯片)装载更大的模型,或者在同等内存容量下运行得更快(因为减少了数据移动量),从而显著优化基础模型的总拥有成本(TCO)和能效(性能功耗比)。
2. Auradine
公司定位: 区块链和AI基础设施解决方案领导者。
这家公司最初以其高性能、高能效的比特币挖矿系统(Teraflux™)而闻名,但它已将其在高速芯片设计和系统工程方面的深厚专业知识扩展到了AI领域。
-
核心技术(AI相关): 公司成立了一个名为 "AuraLinks AI" 的新业务部门,专注于解决AI数据中心的网络瓶颈问题。
-
主要功能: AuraLinks 致力于开发基于开放标准的高速、低延迟网络互连(Interconnects)和交换矩阵(Fabrics)。这是专为支持大规模生成式AI(GenAI)训练和推理工作负载而设计的。
-
目标: 目标是打破当前专有网络(如NVIDIA的InfiniBand)的壁垒,提供可互操作、可扩展且高效的网络解决方案,以最大化GPU利用率并最小化通信延迟。他们是Ultra Accelerator Link (UAL) 和 Ultra Ethernet Consortium (UEC) 等开放标准联盟的成员。
-
与PPT主题的关联: 正如PPT标题“互连 (Interconnects)”所言,Auradine 提供的技术是优化基础模型所必需的另一半拼图。当模型规模大到需要跨越数千个GPU(即“横向扩展”)时,GPU之间的数据通信速度(即互连)就成了最大的性能瓶颈。AuraLinks的目标就是解决这个瓶颈。
Topic1: AI模型的 内存压缩
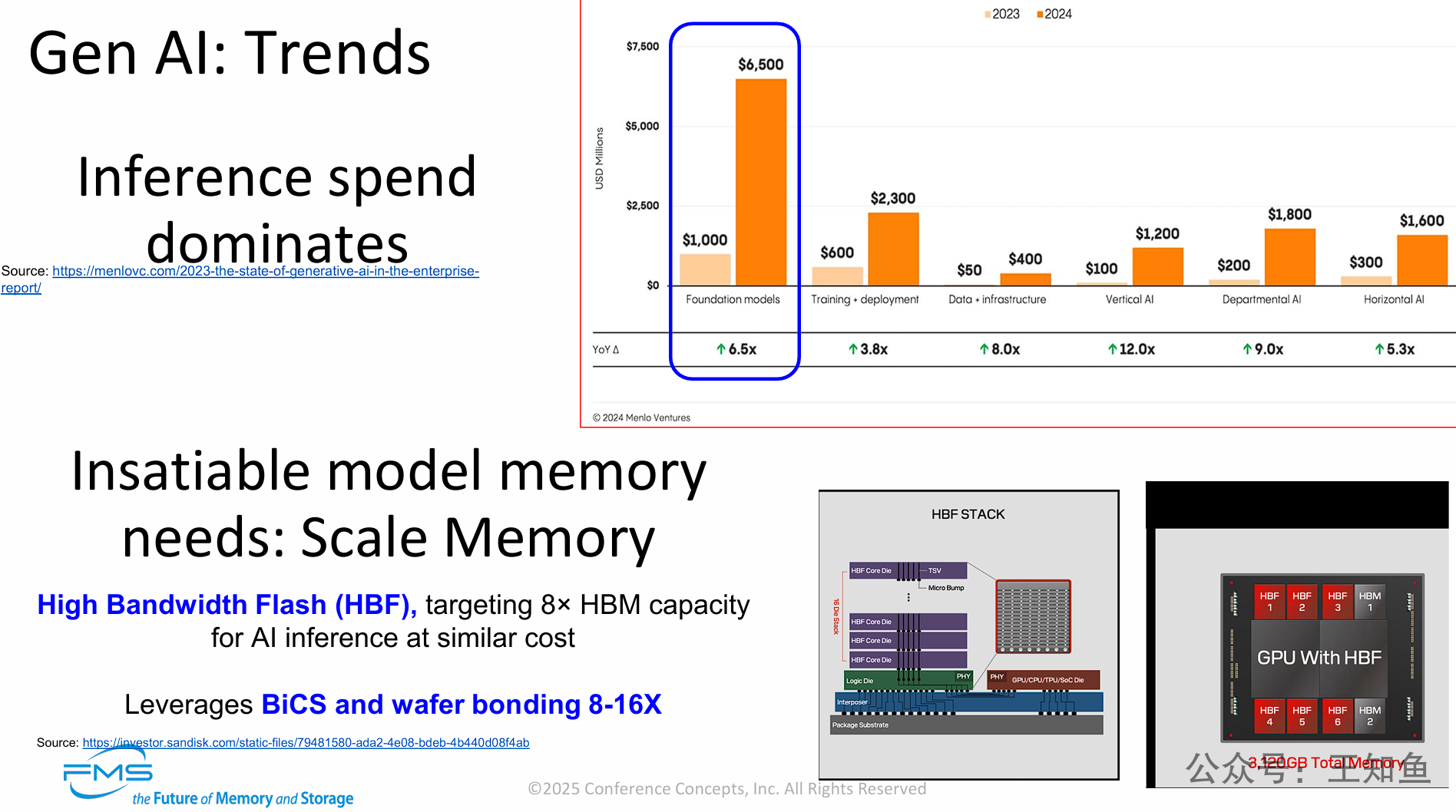
AI 推理占资本投入的绝对数值,而AI推理中内存消耗问题尤为突出。
-
市场背景: 生成式AI市场正经历爆发式增长,特别是在“基础模型”上的支出(预计2024年达65亿美元),这导致了AI推理(Inference) 成为主要的支出领域。
-
技术挑战: 运行这些日益庞大的基础模型,产生了对内存“永不满足”的需求,而现有的HBM技术在容量上已成为严重瓶颈。
-
解决方案: 业界正在探索名为HBF(高带宽闪存) 的新型“扩展内存”技术。
-
HBF的价值: HBF通过采用BiCS 3D NAND和晶圆键合堆叠技术,旨在以接近HBM的成本,提供高达8倍的内存容量。
-
最终效果: HBF技术使得GPU等AI处理器能搭载超大容量内存(如图例中的3,120GB),从而根本上解决AI推理时因模型过大而导致的内存容量瓶颈。

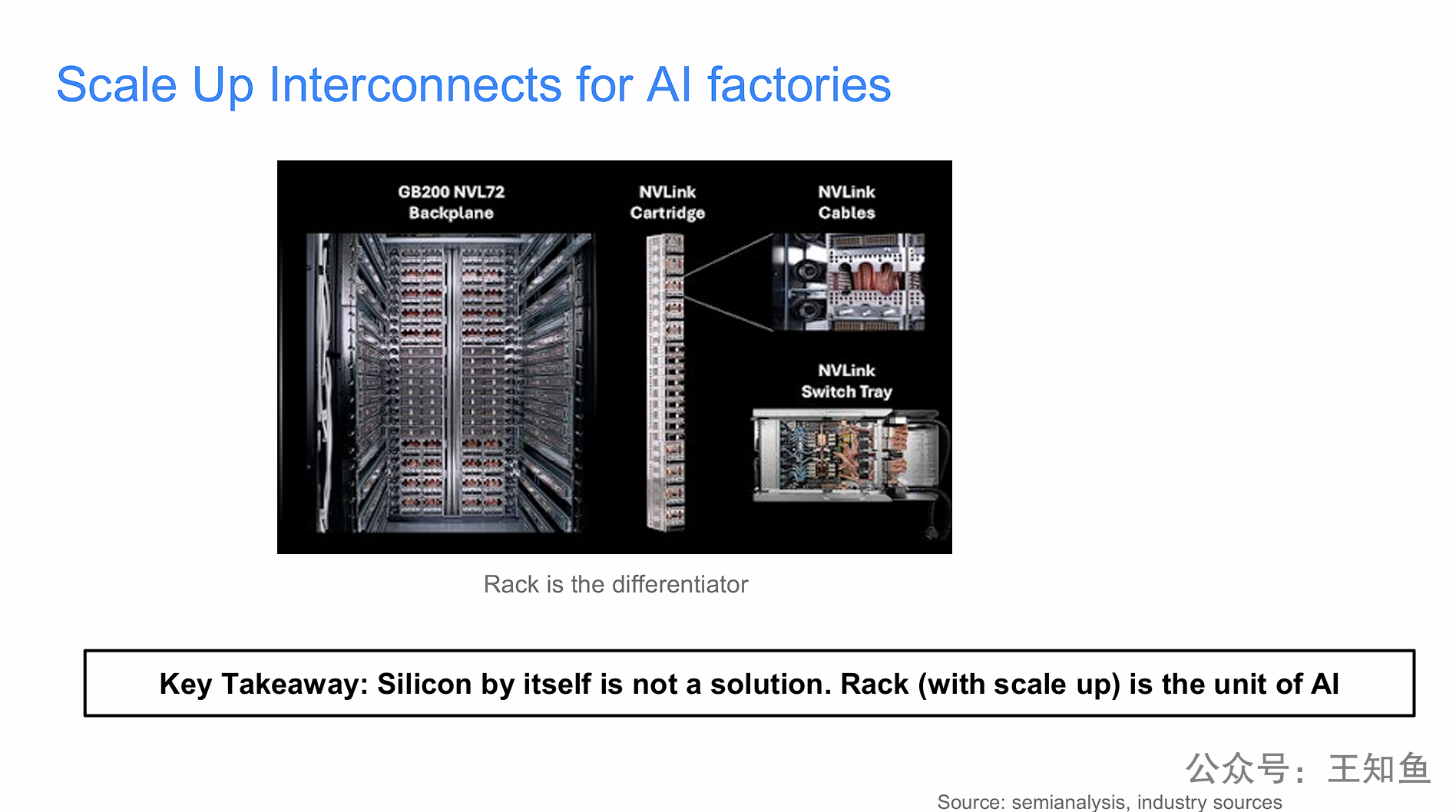
在生成式AI时代,AI性能的巨大飞跃不再仅仅依赖于单个GPU芯片的迭代(如2倍的提升),而是更多地来自于整个机架系统的架构创新,特别是“机架级互连(Rack level interconnects)”技术。
通过对比发现,芯片性能只提升了2倍,但整个机架系统的性能却飙升了30倍。这个巨大的差距(30x vs 2x)明确地指向了互连技术和纵向扩展网络(Scale-up Networking)(例如NVIDIA的NVLink交换矩阵)是实现这种巨大性能增益的关键因素。
AI的竞争已经从“芯片之争”转向了“系统和互连之争”。
AI基础设施的竞争焦点已经发生了根本性转变:单个的AI芯片(Silicon,即GPU)不再是决定性能的唯一因素,真正构建起护城河的是集成了高速“纵向扩展(Scale Up)”互连技术的“整个机架(Rack)”。 演讲者明确提出,在AI工厂的时代背景下,“机架”已经取代“芯片”,成为了AI计算的新基本单元。

虽然LLM(大语言模型)的推理过程包含计算受限(Prefill)和内存受限(Decode)两个阶段,但由于真正消耗时间、占主导地位的 "Decode" 阶段是完全受限于内存的,因此整个LLM推理任务的性能瓶颈是内存 (Memory Bound),而不是计算 (Compute Bound)。
演讲者通过一个Llama 2 7B模型在NVIDIA GPU上的Roofline模型分析数据,提供了强有力的证据:在Decode阶段,所有计算层的瓶颈都指向了“内存”。
这个结论是后续讨论“内存压缩”和“高带宽闪存(HBF)”等技术的前提——即强调解决内存瓶颈是提升AI推理性能的关键。

为了解决LLM推理的“内存受限”瓶颈,不同的AI加速器厂商正在采用截然不同的“内存层次结构”,而这已经成为AI机架方案的关键差异化因素。
PPT通过两个表格的数据对比,有力地证明了这一点:
-
市场现状: 市场上的AI机架内存容量差异巨大,从Groq的0.2TB (纯SRAM) 到NVIDIA的2.56TB (纯HBM),再到Cerebras的1200TB (SRAM + Flash混合架构)。
-
技术路径分化: NVIDIA和AMD受困于HBM的容量限制(尽管带宽极高),其机架总内存只能达到个位数TB级别。
-
新兴解决方案: Cerebras和SambaNova等公司则通过集成闪存(Flash) 到其内存架构中,构建了“富存储”的混合内存层次,从而将机架总内存容量提升了数百倍(1200 TB vs 2.56 TB),以此作为其核心竞争力来解决超大模型的内存瓶颈。

为优化推理过程,紧张的内存资源,业界对模型内存优化提出压缩方案。
必须区分两种模型压缩方式,以解决AI内存瓶颈。
-
传统的“有损压缩”(量化、剪枝) 在训练时进行,虽然能缩小模型,但会牺牲模型精度并带来高昂的重训练成本(精度控制和优化成为模型开发公司的核心技术),短时间内市场尚不敏感,但长期来看并非理想方案。
-
“无损压缩” 是一种在运行时(runtime)实时压缩内存数据的技术,它不会牺牲任何精度。
-
然而,并非所有无损压缩都适用。标准的无损算法(如ZSTD, LZ4)因为压缩率低、延迟高(微秒级)、处理块大(KB级),无法用于高速内存。
-
演讲者(ZeroPoint)提出的专有“Cacheline算法” 才是关键解决方案:它能以纳秒级延迟在64字节的超小颗粒度上实现1.5倍以上的无损压缩,这使其能被硬件加速并“透明地”集成到内存子系统中。
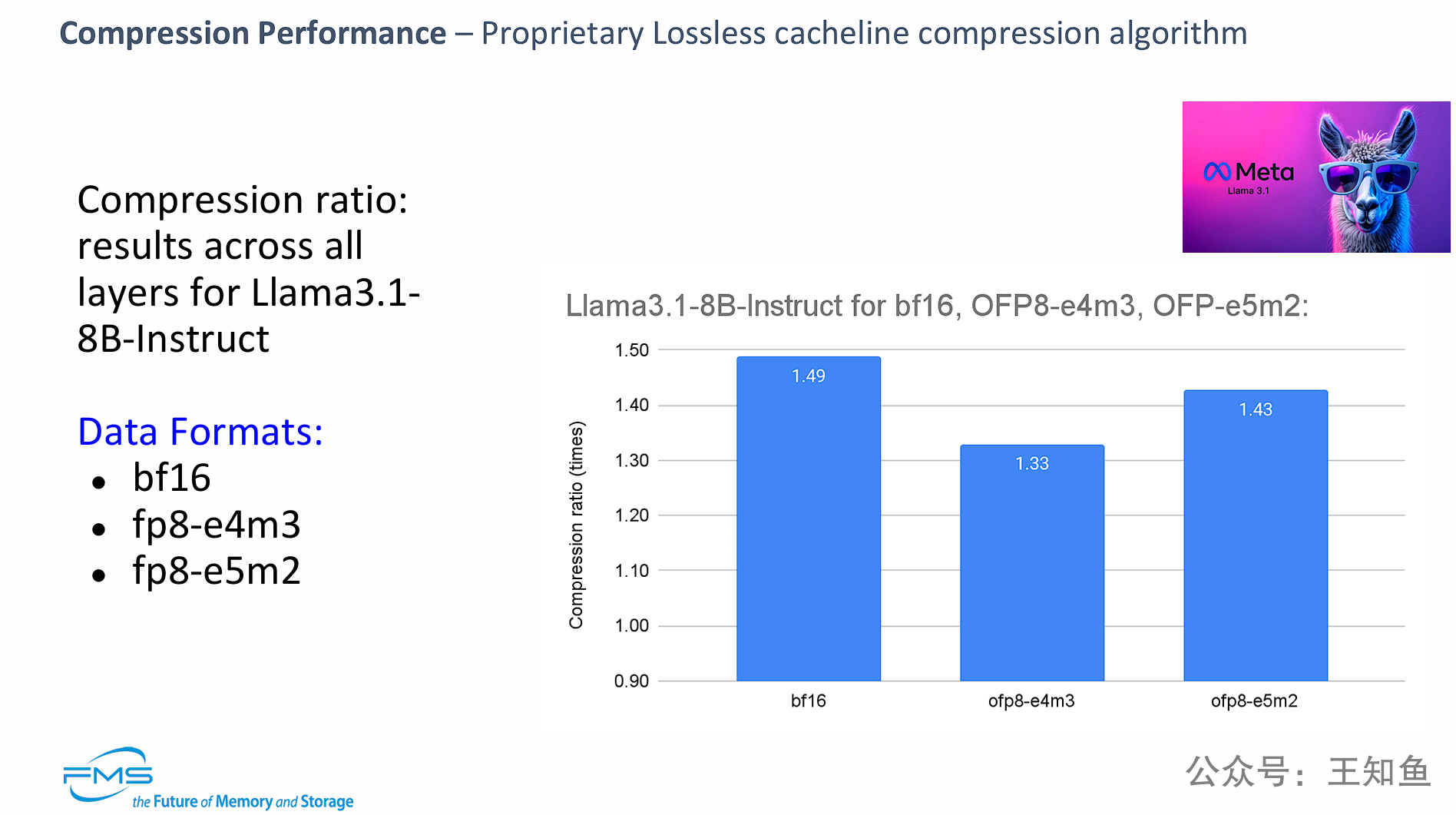
通过在Llama 3.1 8B模型上的基准测试数据,证明了其专有的“无损缓存行压缩算法”的有效性。
-
该算法可以实现显著的内存压缩,在
bf16格式上接近1.5倍。 -
更关键的是,即使在
fp8这种本身已经经过“量化”(一种有损压缩)的高度优化的数据格式上,该算法依然可以提供额外的、无损的压缩(1.33x - 1.43x),从而在不牺牲任何模型精度的情况下,进一步大幅减少内存占用。
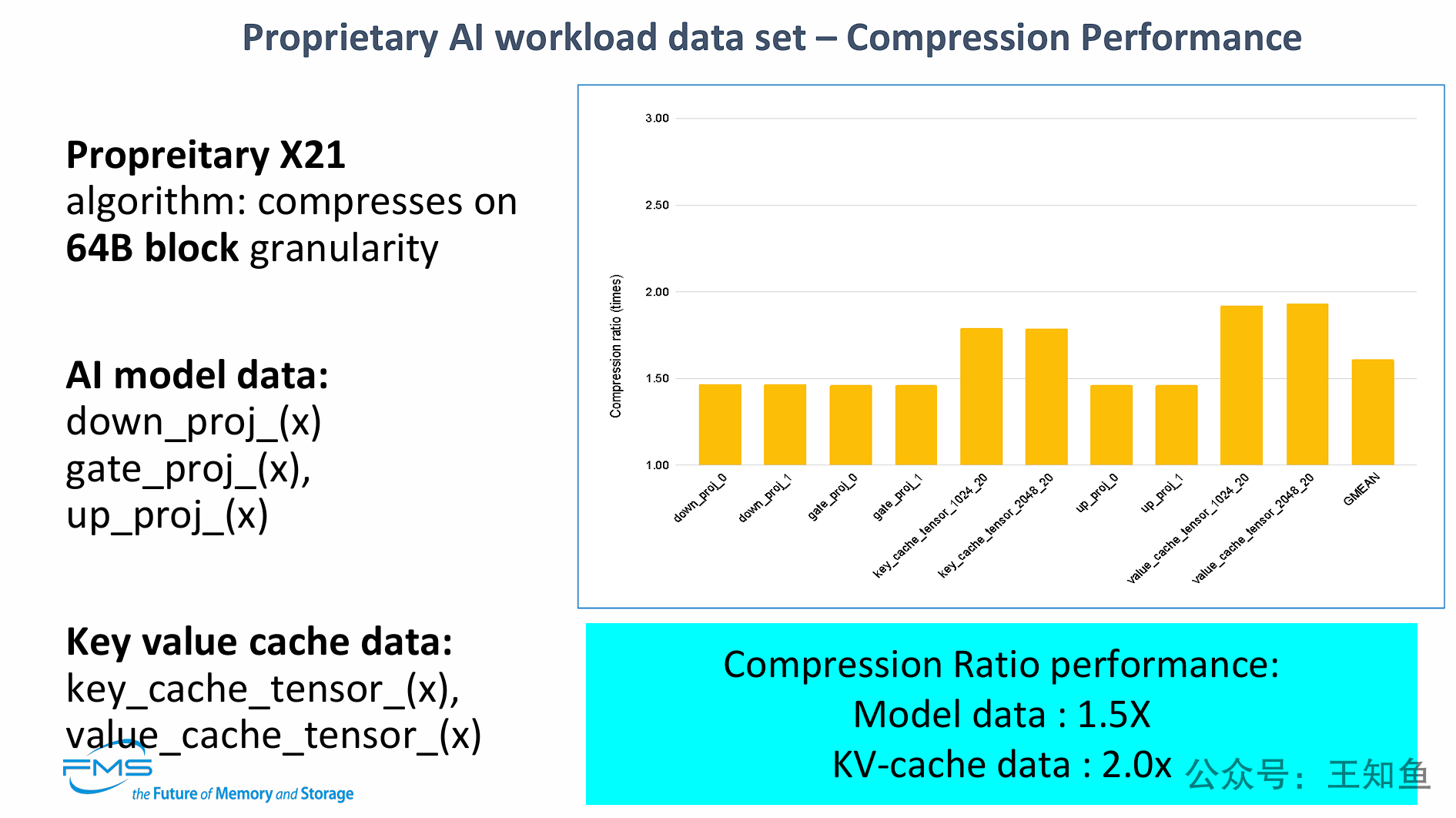
PPT展示了其专有的X21算法(64B粒度)在AI工作负载上的详细压缩性能。
核心观点是:该算法不仅能压缩模型权重,还能更有效地压缩KV缓存。
它将AI推理中的关键内存占用分为两类,并给出了不同的压缩性能数据:
-
AI模型数据(权重): 可实现 1.5倍 的无损压缩。
-
KV缓存数据(推理上下文): 可实现高达 2.0倍 的无损压缩。
这一发现尤其重要,因为KV缓存是导致LLM推理(特别是Decode阶段)成为“内存受限”的关键瓶颈之一。能将其压缩2.0倍,意味着在不牺牲任何精度的情况下,有效内存容量翻倍,极大地缓解了内存瓶颈。
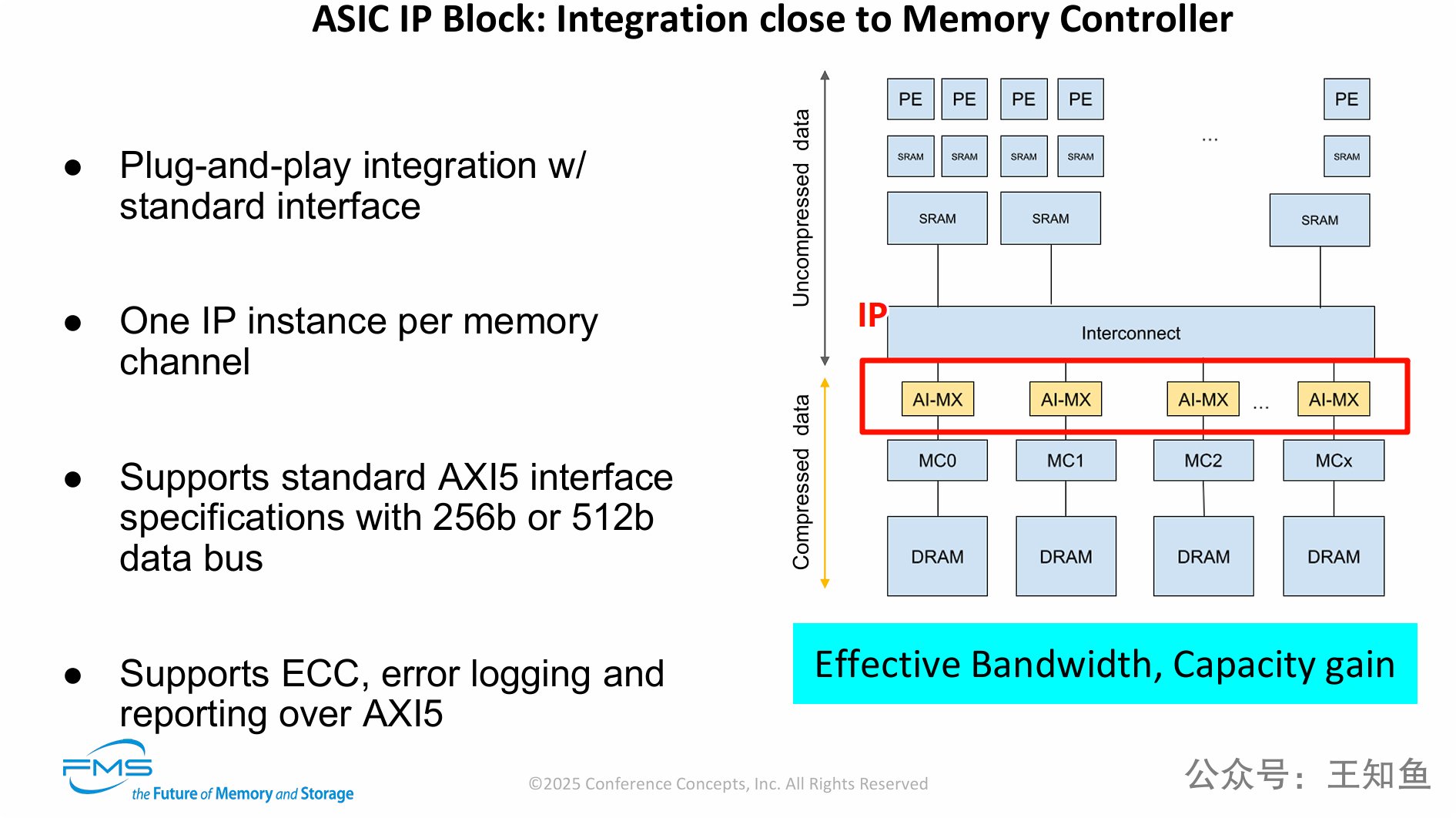
PPT详细阐述了ZeroPoint公司压缩技术(即AI-MX)的商业化实现方案和集成架构。
核心观点是:该技术是一个可即插即用的ASIC IP模块,它被“透明地”集成在AI处理器的互连总线与内存控制器之间。
通过在每个内存通道上实时地、硬件加速地执行无损压缩和解压缩,该方案在处理器核心完全无感知的情况下,为系统带来了有效内存容量和有效内存带宽的双重巨大提升,从而直接解决了LLM推理的内存瓶颈。
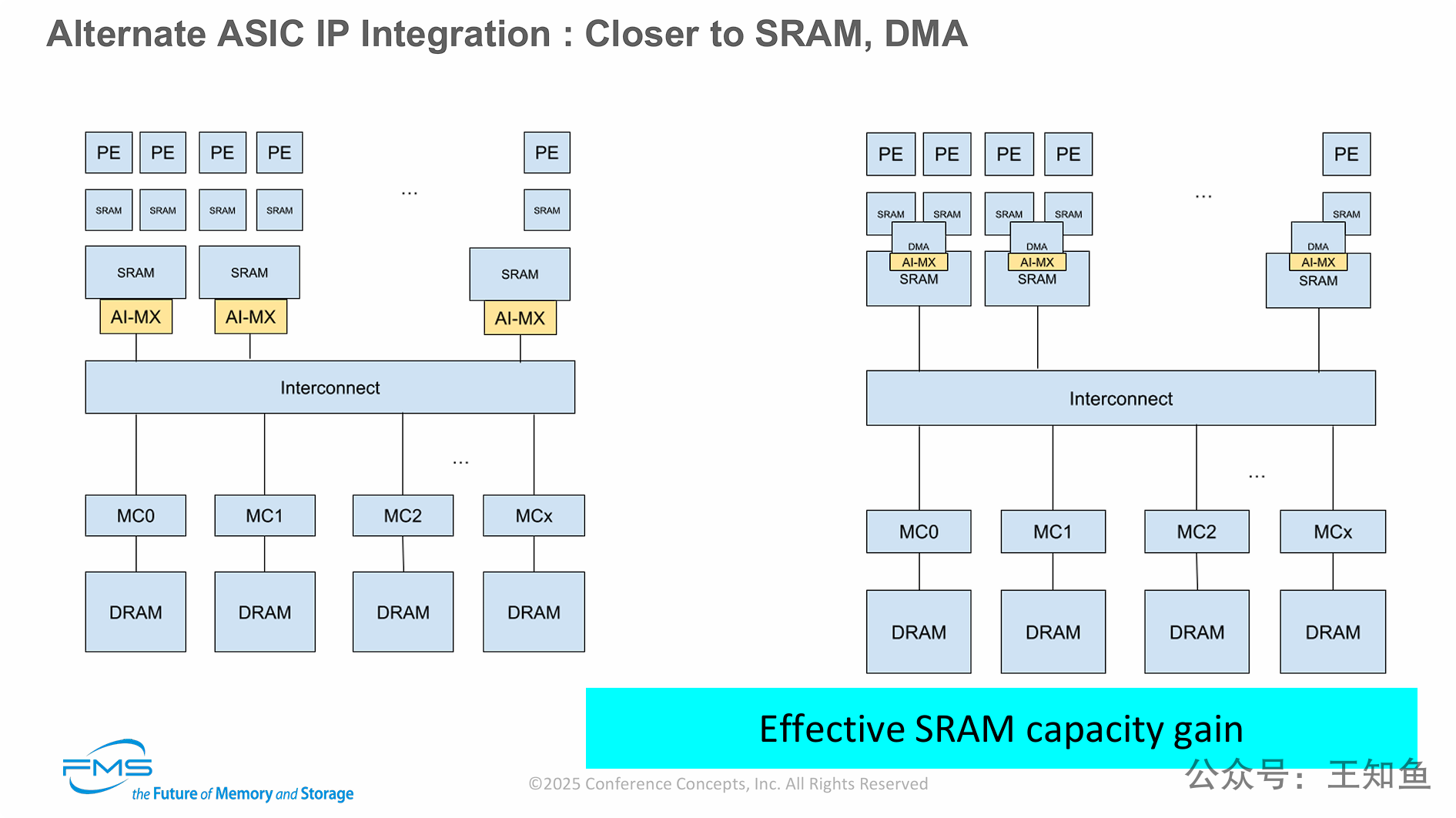
PPT展示了 “AI-MX” 硬件压缩IP的另外两种集成方案,强调了其部署的灵活性。
与上一张PPT中将其部署在DRAM内存控制器旁(旨在提升DRAM容量和带宽)不同,本页的方案将IP模块上移到内存层次结构中更靠近计算核心的位置,将其与SRAM(片上缓存)或DMA引擎相集成。
这种集成方案的核心收益是:实现“有效的SRAM容量增益”。由于SRAM(尤其是L2/L3缓存)是AI芯片中极其宝贵(昂贵且面积大)的资源,对其进行透明压缩(例如1.5x-2.0x)可以成倍提升其有效容量,从而显著减少对慢速主内存(DRAM)的访问,带来巨大的性能提升。
Topic 2:机架级互联

PPT总结了实现“机架规模AI”所依赖的两大技术飞跃:
-
物理层革命: 为了在机架内塞入数千根高速线缆,业界正转向使用线缆背板、有源中板和下一代连接器(如CPO)。这些技术不仅解决了信号完整性(SI)和散热问题,还显著降低了互连系统自身的功|耗(例如从8kW降到2kW),为AI计算单元释放了宝贵的电力预算。
-
网络拓扑革命: 简单的GPU直连已死,交换矩阵式网络(Switched Fabrics) 成为标准。这种架构不仅提供了线性扩展能力,其最重要的价值是实现了 “网络内计算”(如AllReduce Offload),让交换机分担AI通信负载,这是实现AI性能指数级提升的关键。
===
Topology Evolution (拓扑演进)
这部分讨论了AI集群的网络架构的演变。
要点 1: “Switch-based fabrics are baseline beyond 8-16 GPUs” (交换矩阵式网络是超越8-16个GPU规模的基准方案)。
- 转变: 当GPU数量较少时(如8卡),可以使用GPU间的直连网状网络(如NVLink);但对于机架规模(如72卡)及更大规模,必须采用交换矩阵 (Switch-based fabrics) 架构。
要点 2:Advantages over direct mesh (相比直连网状网络的优势)
“Linear scalability (avoid O(N²) link explosion)” (线性扩展能力,避免O(N²)的链路爆炸)。交换矩阵的连接数是线性 (O(N)) 增长的,而直连网络是指数级 (O(N²)) 增长的。
“In-network collective offloads (AllReduce in-switch)” (网络内集合通信卸载,例如在交换机内完成AllReduce)。这是最关键的优势之一:交换机本身可以承担一部分AI计算(如AllReduce聚合操作),极大地释放了GPU的计算和通信负担。
“Easier vPod creation & dynamic partitioning” (更容易创建虚拟Pod和动态分区)。提高了资源调度的灵活性。
“Better cable management & SI via leaf-spine” (通过Leaf-Spine架构实现更好的线缆管理和信号完整性)。
右下角架构图对比:
左图(传统方案): 展示了一个连接4000个GPU的传统3级(Leaf-Leaf-Spine)数据中心网络。它需要多层、多种交换机(25.6T, 51.2T),占用12U机架空间,功耗高达约600kW。
右图(现代AI Fabric方案): 展示了一款Cisco的现代AI交换机 (Single N9364E-SG2),它可以作为一个2U的独立交换机来构建一个AI Pod。
对比结论: 现代AI交换矩阵架构(如右图所示)相比传统数据中心网络(如左图所示),可实现 75%的能效节省 和 83%的机架空间节省。
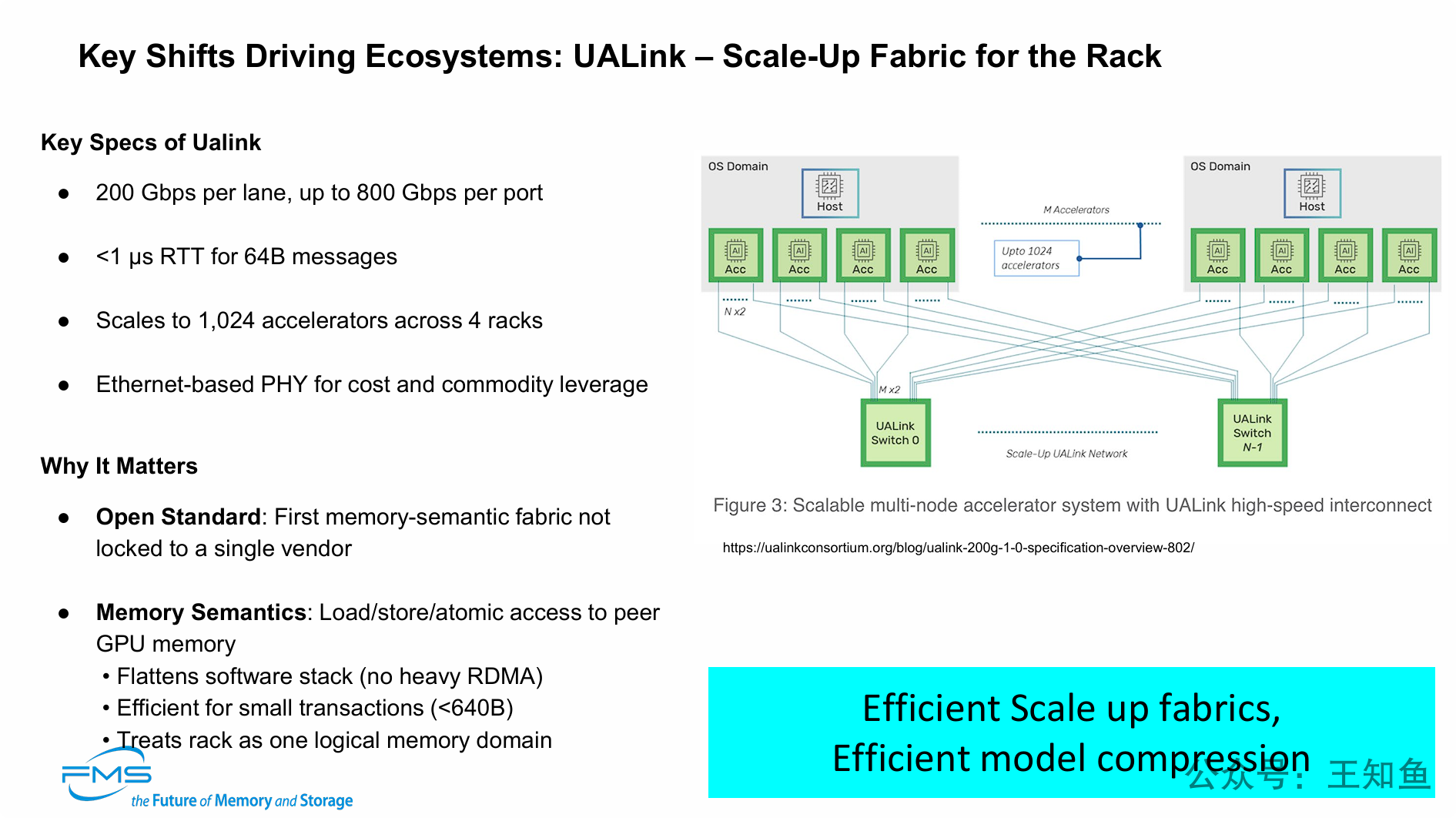
PPT转向了演讲标题中的“互连 (Interconnects)”部分,并提出了 UALink (Ultra Accelerator Link) 作为AI生态系统的关键转变点。
-
AI互连需要开放标准: 行业需要一个像UALink这样的开放标准来打破NVIDIA NVLink的供应商锁定。
-
AI互连需要“内存语义”: UALink的核心优势是“内存语义”,它允许GPU像访问本地内存一样直接、低延迟(<1µs)地访问其他GPU的内存,无需低效的RDMA协议,这对小事务处理尤为高效。
-
UALink实现“机架即内存”: UALink的目标是将多达1024个加速器连接成一个统一的逻辑内存域,完美实现了“机架是AI基本单元”的架构理念。
演讲的三大核心论点和一个最终呼吁
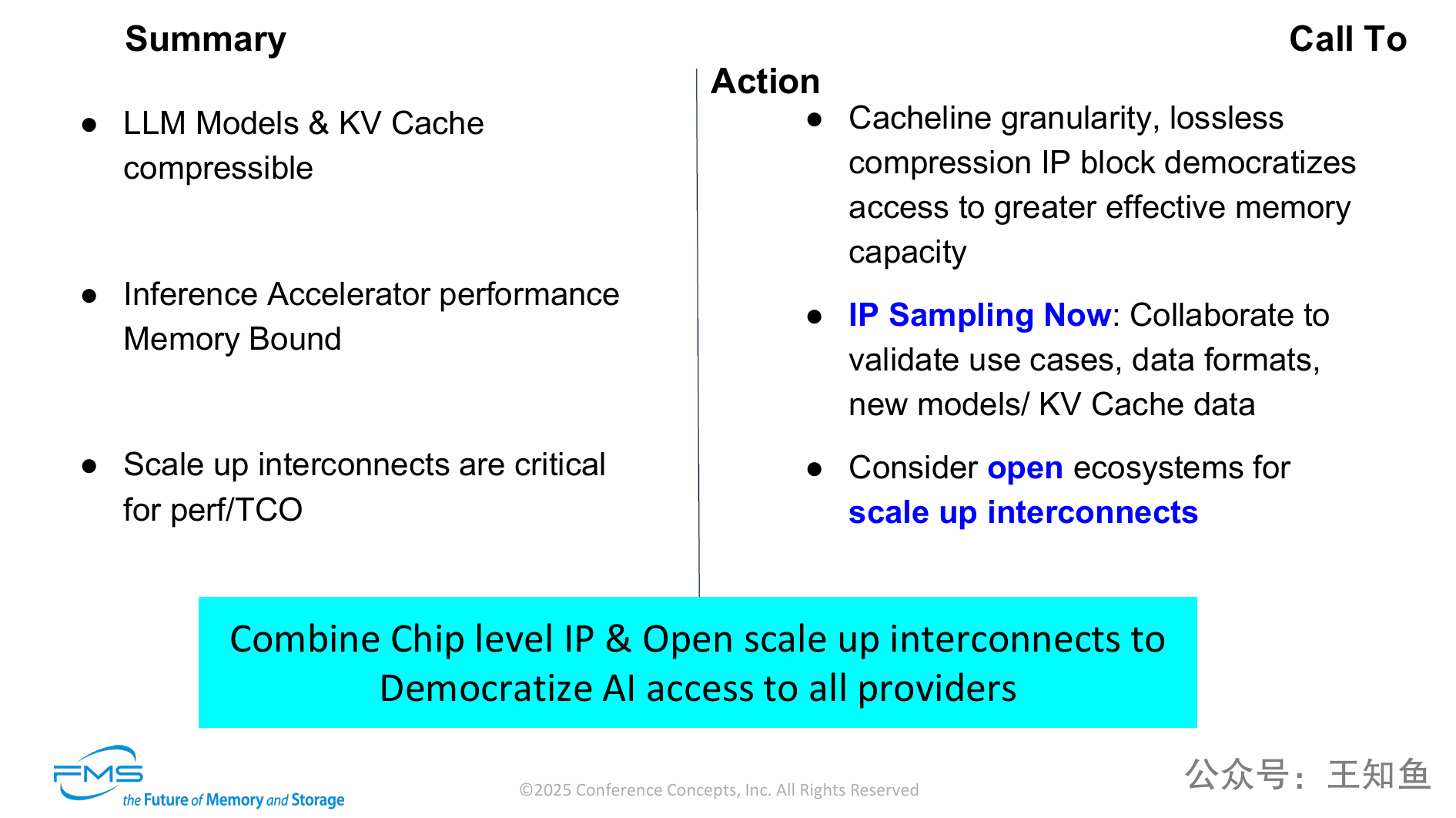
[!summary]
三大核心论点 (Summary):
问题在于内存: AI推理性能受限于内存(Memory Bound)。
机架级是关键: 纵向扩展的机架级互连技术(Scale-up Interconnects)是解决性能/TCO的关键。
压缩是可行的: LLM模型和KV缓存都可以通过专有硬件(IP)进行高效的无损压缩。
一个最终呼吁 (Call To Action & Conclusion): 演讲者呼吁业界采取“两条腿走路”的开放策略来实现“AI民主化”:
在芯片内部 (纵向),采用 ZeroPoint 的芯片级IP 来实现透明的内存压缩,以倍增有效内存容量和带宽。
在机架内部 (横向),采用 Auradine 所倡导的开放互连生态(如UALink) 来取代专有方案。