
AI向量搜索新范式:计算存储如何破局?
问题意识
Lowering TCO of Vector Search in Al With Flash-Driven Efficiency
VISHWAS SAXENA,SENIOR TECHNOLOGIST
AABHA MISHRA,SENIOR ENGINEER
在人工智能和机器学习飞速发展的今天,大模型(LLM)、推荐系统、语义搜索等应用已成为我们日常生活中不可或缺的一部分。然而,这些应用的背后,一项名为近似最近邻(ANN)搜索的核心技术正面临着前所未有的挑战。您是否曾困惑于,在处理海量高维向量数据时,如何在保证搜索效率和准确性的同时,有效控制高昂的硬件成本和有限的存储容量?传统的GPU加速方案性能卓越却成本高昂,而基于磁盘的方案虽然经济实惠却又牺牲了响应速度。面对这种性能与成本的“鱼与熊掌”困境,业界究竟有没有一种创新的解决方案,能够打破僵局,实现真正的平衡?本文将深入探讨这一核心问题,并为您揭示一种颠覆性的技术路径。
阅读收获
- 深入理解近似最近邻(ANN)搜索在现代AI/ML应用中的关键作用,并掌握基于图的索引算法为何成为主流。
- 清晰辨析当前高性能ANN方案(如NVIDIA CAGRA)与大规模低成本方案(如微软DiskANN)各自的优势与局限性,以及它们在性能、成本和容量上的权衡。
- 洞察SanDisk如何通过计算存储这一创新架构,将计算能力下沉至存储层,从而有效解决ANN搜索在磁盘I/O和距离计算上的两大性能瓶颈。
思考与讨论
- SanDisk的计算存储方案在向量搜索领域展现出巨大潜力,您认为这种“计算靠近数据”的理念,在其他AI/ML工作负载(如数据预处理、模型训练或推理)中,是否也能复制其成功,并带来类似的效率提升和成本优化?
- 随着AI模型和数据规模的持续爆炸式增长,您认为未来ANN搜索技术还将面临哪些新的挑战?除了计算存储,还有哪些潜在的创新方向(例如量子计算、新型内存技术)值得我们关注和探索?
- 在您实际负责的AI解决方案部署中,面对极致性能(如纯GPU方案)与成本/容量(如计算存储方案)之间的权衡,您会如何根据具体的业务场景和SLA要求,做出最优的技术选型和架构设计?
👉 划线高亮 观点批注
Main

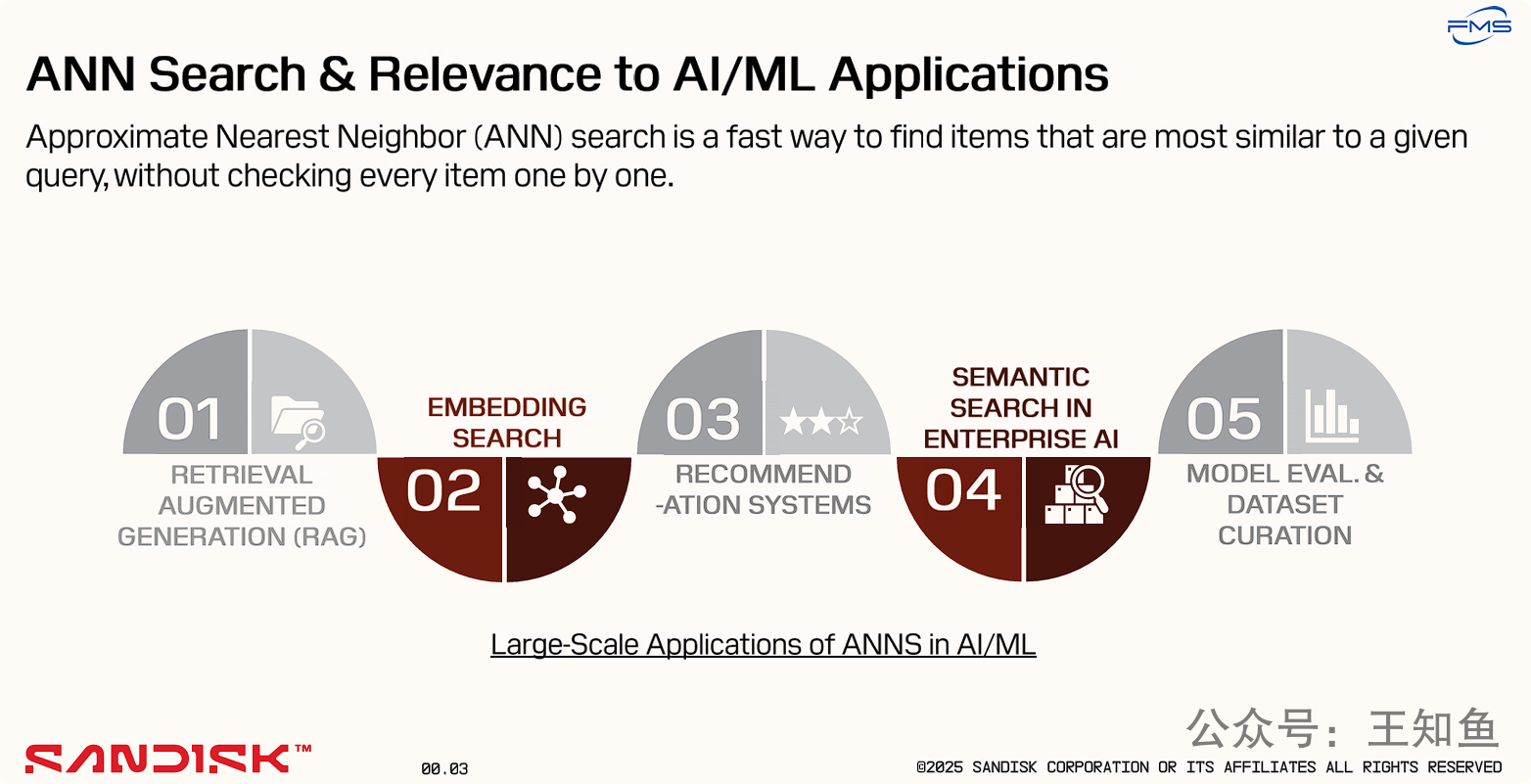
PPT的核心目的是强调近似最近邻(ANN)搜索是现代人工智能和机器学习应用的一项基础性、关键性技术。
它通过两个层面来阐述这一观点:
-
清晰定义: 首先,它明确解释了ANN搜索是什么——一种高效的相似性搜索技术。
-
展示价值: 其次,它列举了五个当前最重要、最流行的大规模AI应用场景(RAG、推荐系统、语义搜索等),并指出ANN搜索是实现这些应用的核心技术支撑。
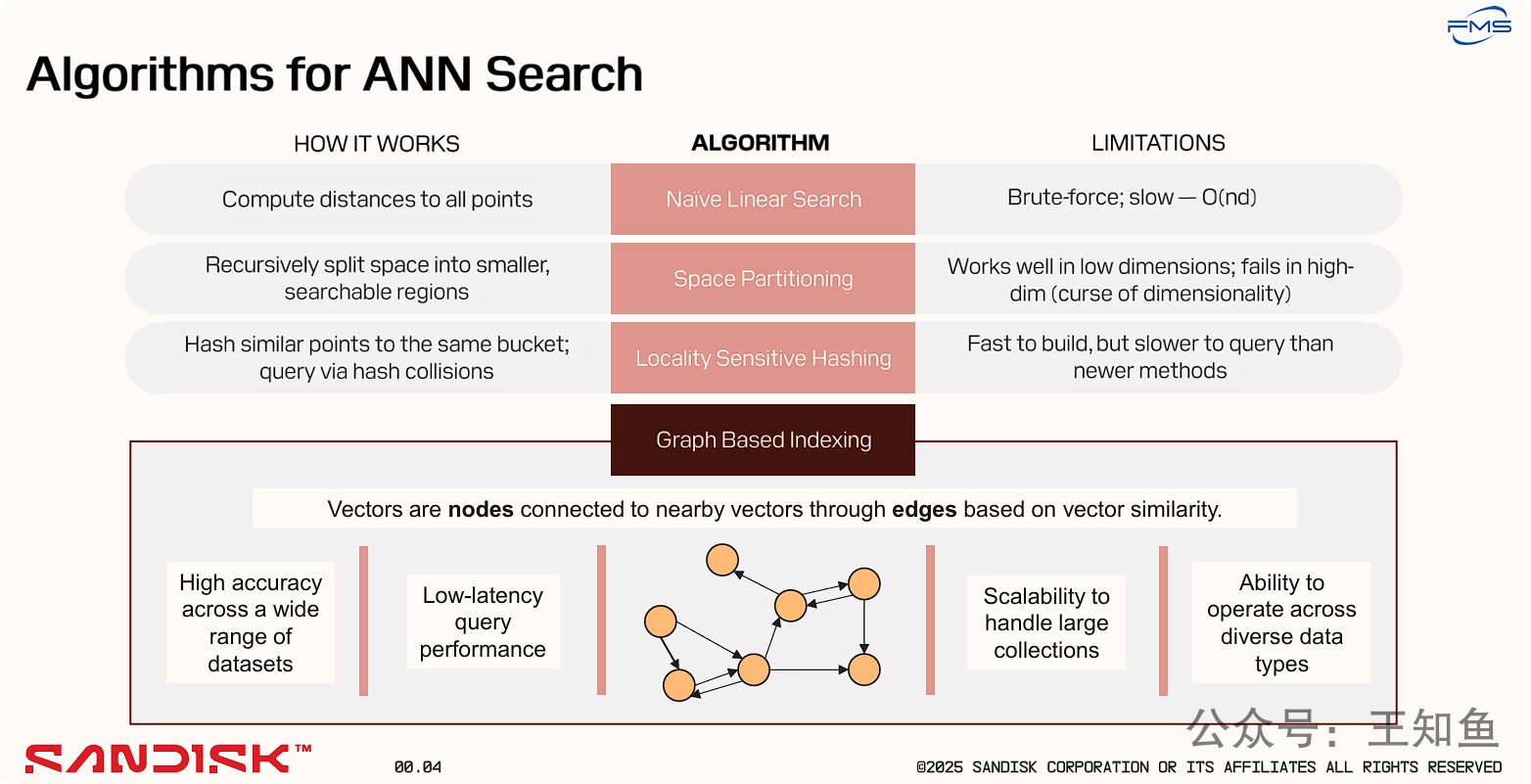
在多种ANN搜索算法中,基于图的索引(Graph-Based Indexing)是当前综合表现最优异的主流技术。
-
对比与排除: 它首先简要介绍了其他几种算法(线性搜索、空间分区、LSH),并明确指出了它们的致命弱点,暗示这些并非理想选择。
-
重点推荐: 随后,它将焦点完全集中在“基于图的索引”上,详细阐述了其工作原理,并罗列了其在准确率、查询延迟、可扩展性和通用性四个关键维度上的显著优势。
===
经典ANN 算法及其局限性
| 算法名称 | 工作原理 | 局限性 |
|---|---|---|
| Naive Linear Search (朴素线性搜索) | 计算查询向量与数据集中所有点之间的距离。 | 这是“暴力”(Brute-force)搜索,速度非常慢,其时间复杂度为 $O(nd)$(n是向量数量,d是向量维度)。这通常被用作衡量准确率的基准(ground truth),而非实用的ANN算法。 |
| Space Partitioning (空间分区) | 采用递归方式将整个向量空间分割成更小的、可搜索的区域。常见的算法有KD树(k-dimensional tree)、R树等。 | 在低维度数据上表现良好,但在高维度数据时性能会急剧下降,这就是所谓的“维度灾难”(curse of dimensionality)。 |
| Locality Sensitive Hashing (LSH, 局部敏感哈希) | 使用特殊的哈希函数将相似的点(向量)映射到同一个“桶”(bucket)中。查询时,通过哈希冲突来找到邻近的向量。 | 索引构建速度快,但查询速度通常比更新的方法要慢,且为了保证召回率,往往需要多个哈希表,导致内存占用较大和调优复杂。 |
ANN-图算法优势
-
在各种数据集上都能实现高准确率: 相比其他方法,图算法通常能达到最高的搜索精度。
-
低延迟的查询性能: 一旦图索引构建完成,查询过程非常快速。
-
可扩展以处理大规模数据集: 能够有效地处理包含数十亿向量的庞大数据集。
-
能够处理多种数据类型: 只要数据能被转换为向量(embedding),无论是文本、图像还是其他类型,都可以使用此方法。
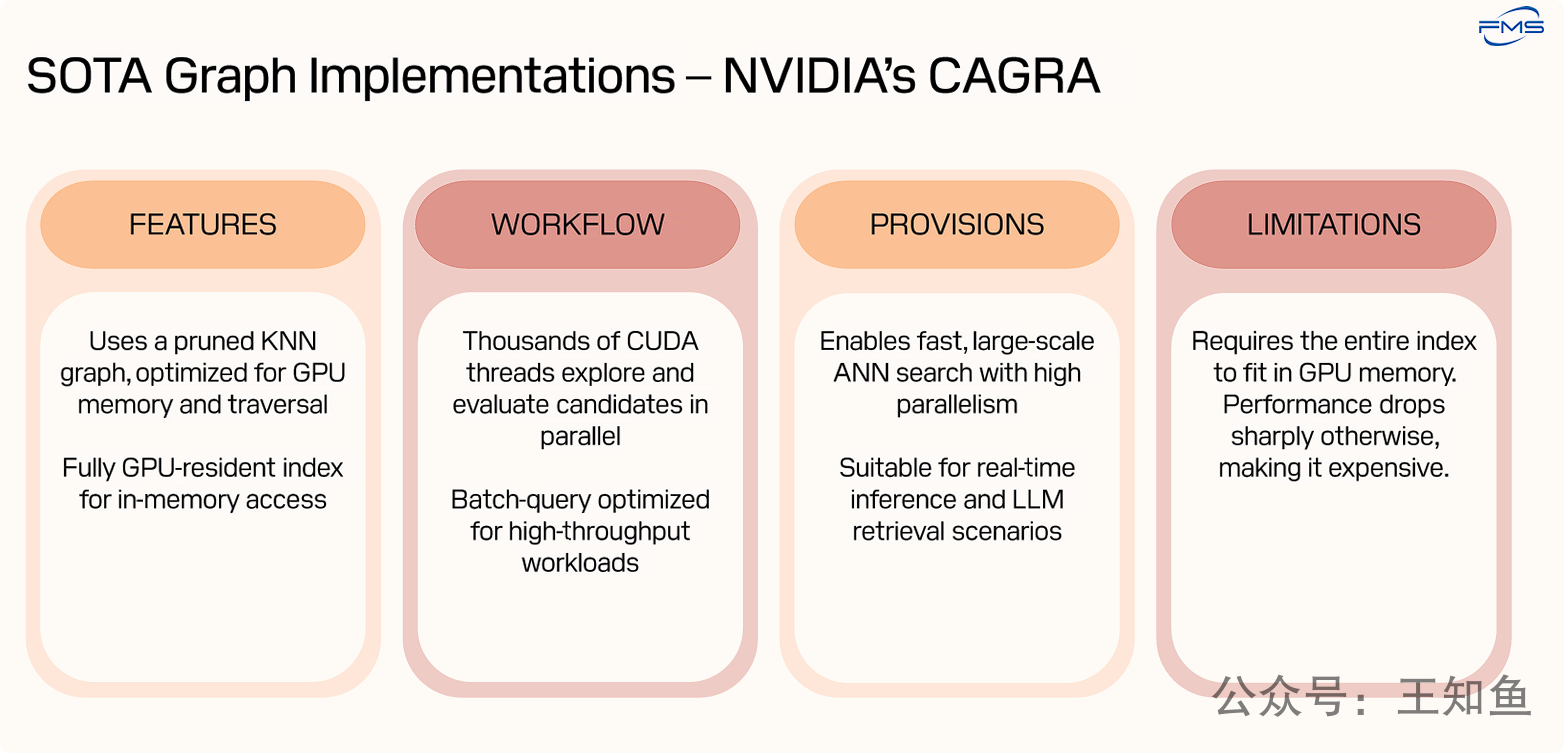
CAGRA (CUDA-Accelerated Graph-based Nearest Neighbor Search) 是NVIDIA推出的一个基于GPU加速的图ANN搜索库。
-
FEATURES (特性):
- 采用优化的剪枝K-近邻图,降低复杂度,适合GPU高效存储和快速搜索。
- 整个索引完全加载到GPU显存,实现极低延迟的内存内操作。
-
WORKFLOW:
- 利用GPU大规模并行计算,数千线程同时搜索和计算距离,实现高速搜索。
- 支持批量查询,最大化GPU利用率,提供高吞吐量。
-
PROVISIONS:
- 借助GPU并行能力,实现快速、大规模近似最近邻搜索。
- 适用于实时AI推理和LLM检索等低延迟场景。
-
LIMITATIONS:
- 索引必须完全放入有限且昂贵的GPU显存。
- 超出显存会导致性能骤降,需使用昂贵的大显存GPU,成本高昂。
===
尽管以NVIDIA CAGRA为代表的纯GPU方案是当前ANN搜索的性能标杆,但它存在一个根本性的、与成本直接相关的架构缺陷——对昂贵且有限的GPU显存的强依赖。
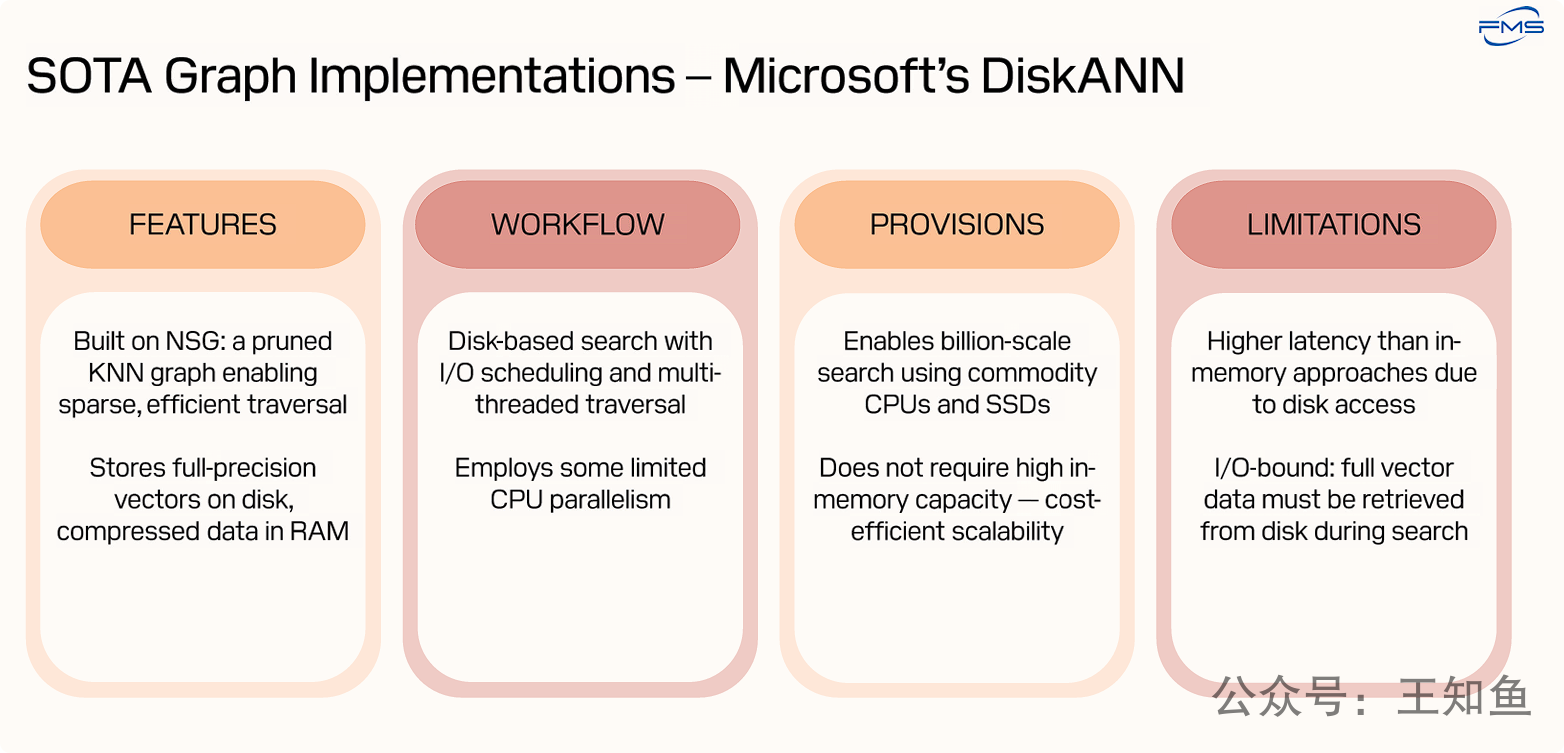
微软的DiskANN方案通过创新的“内存+磁盘”混合架构,成功解决了ANN搜索的“大规模扩展性”和“成本”问题,但代价是牺牲了查询延迟。
-
优势: DiskANN是成本和容量方面的赢家。它使得在商用硬件上部署和扩展超大规模(十亿级甚至更高)的向量搜索引擎成为可能,极大地降低了TCO(总拥有成本)。
-
劣势: 它的性能瓶颈在于存储I/O,导致延迟较高,因此不适合那些对响应时间有极端要求的实时应用。
通过前后两张PPT(NVIDIA CAGRA vs. Microsoft DiskANN),当前业界的选型路线:
-
要极致性能(低延迟) -> 选GPU方案 -> 就要承受高昂成本和有限容量。
-
要海量容量和低成本 -> 选磁盘方案 -> 就要接受更高的延迟。
===
FEATURES (特性):
- NSG是一种图索引算法,通过剪枝构建稀疏图,减少节点连接数以提高搜索效率。
- 核心设计将全精度向量存于SSD,仅将压缩数据保留在DRAM中,降低成本。
WORKFLOW (工作流程):
- 搜索过程涉及磁盘读取,通过I/O调度和多线程遍历优化延迟与并行计算。
- 并行能力有限,远不及GPU方案(计算能力依靠CPU+DRAM实现,IO产生时延)。
PROVISIONS (提供/带来的好处):
- 使用廉价商用硬件即可处理十亿级向量数据集。
- 避免内存限制,提供高性价比的可扩展性。
LIMITATIONS (局限性):
- 磁盘访问导致延迟高于纯内存方案。
- 性能受I/O限制,搜索时需从磁盘读取完整向量数据,耗时较长。

通过对DiskANN的实际性能数据进行剖析,精确地定位了其两大性能瓶颈——磁盘I/O和距离计算,并由此推导出解决问题的根本方向。
-
从定性到定量: 它不再是宏观地讨论DiskANN“延迟高”的缺点,而是用具体的数字(27% IO 时延+ 30% 搜索计算时延)来证明这个问题的严重性以及问题的根源所在。
-
诊断问题,引出药方: 它明确指出了两个需要被解决的核心问题,并提出了对应的解决思路(“计算靠近数据”和“加速计算”)。
-
将搜索过程更靠近数据:这一条直接针对“磁盘I/O”的瓶颈。其核心思想是,如果计算可以在数据存储的地方(即SSD内部)进行,就可以避免数据在存储设备和主机CPU之间来回传输所带来的延迟。这正是计算存储(Computational Storage) 的核心理念。
-
加速距离计算:这一条直接针对“距离计算”的瓶颈。既然CPU处理这项任务耗时很长,那么就需要使用更高效的方式,例如专用的硬件加速器来执行这些计算。
-
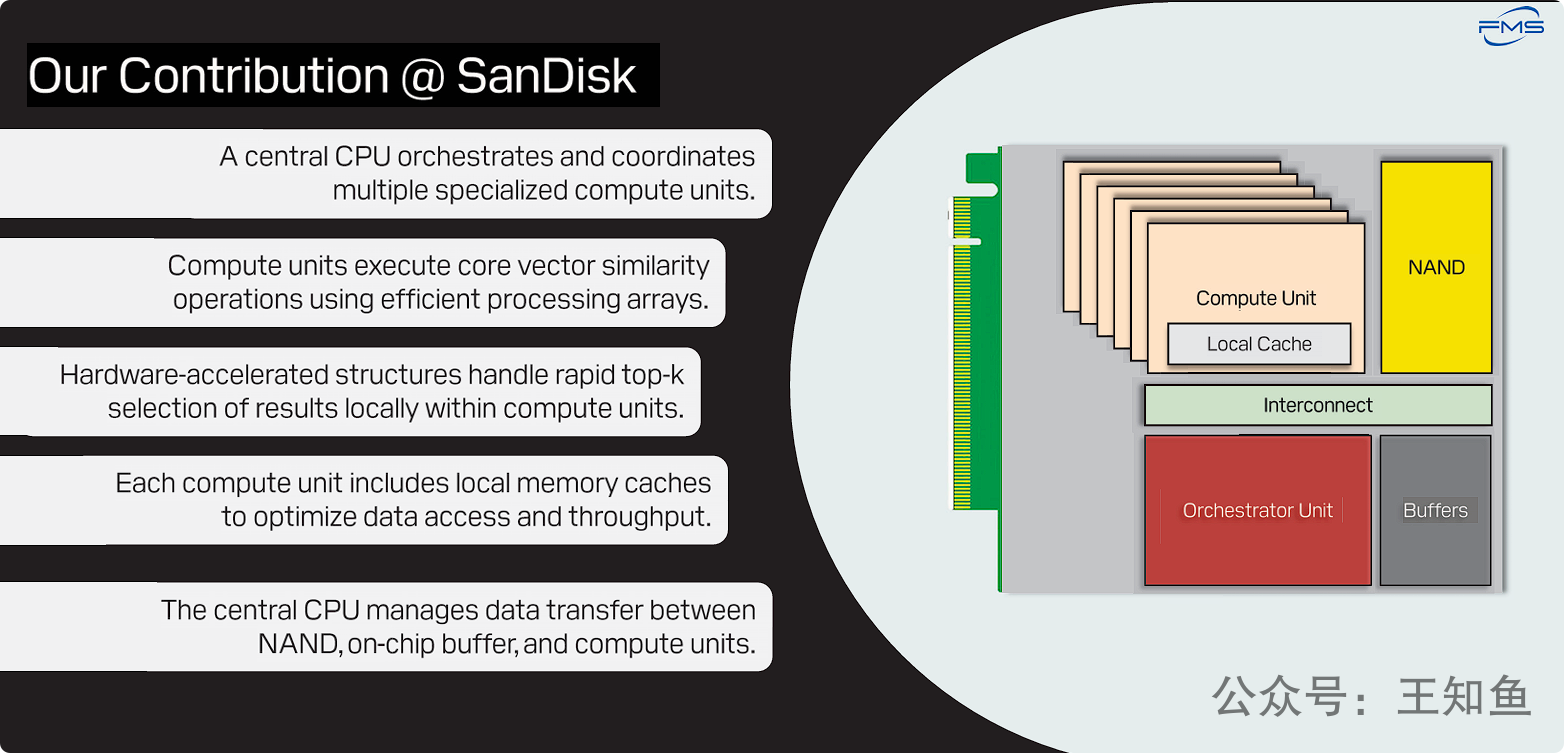
SanDisk的解决方案:一款专为大规模ANN向量搜索设计的、软硬件一体的计算存储(Computational Storage)加速器。
这个方案的创新之处在于,它从根本上解决了之前讨论的行业痛点:
-
解决了DiskANN的I/O瓶颈: 通过将计算(Compute Units)和存储(NAND)集成在同一个设备上,实现了“计算靠近数据”。向量数据无需通过PCIe总线长途跋涉到主机CPU,极大地降低了数据移动带来的延迟,从而解决了I/O-bound的问题。
-
解决了DiskANN的计算瓶颈: 它使用专门的、并行的硬件计算单元来加速距离计算和Top-k筛选,其效率远高于通用CPU,从而解决了计算密集(compute-bound)的问题。
-
解决了纯GPU方案的成本和容量瓶颈: 它以成本低廉且容量巨大的NAND闪存作为主存储介质,而不是昂贵且容量有限的GPU显存,因此能够以极高的性价比支持超大规模(十亿级以上)的向量数据集。
===
右侧:硬件架构图
这是一个计算存储设备(Computational Storage Device)的高度抽象示意图,可能是一个PCIe卡或U.2/E1.S等形态的SSD。其内部主要组件包括:
-
NAND (黄色): 这是NAND闪存芯片,用于持久化存储海量的、完整的向量数据集。
-
Orchestrator Unit (红色): 编排/协调单元。这就是左侧文字中提到的“中央CPU”,是整个设备的大脑,负责任务调度、协调各个计算单元,并管理数据流。
-
Compute Unit (米色): 计算单元。图中有多个计算单元堆叠在一起,表明这是一个并行处理架构。这些是专门设计用来执行向量相似度计算的硬件加速器。
-
Local Cache (计算单元内部): 每个计算单元都内嵌了本地缓存。这是高速内存,用于暂存正在被处理的数据,以减少访问延迟,提升吞吐量。
-
Interconnect (浅绿色): 内部互联总线。它连接了NAND、编排单元、缓冲区和所有计算单元,是设备内部数据传输的高速公路。
-
Buffers (灰色): 缓冲区。这是片上内存,用作从NAND读取数据到计算单元处理之间的中转站。
[!note]
计算型存储概念早就提出,Samsung 在该领域倡议的比较多,从减少数据移动、加解密增强、重删压缩等多个场景讨论过 在端侧存储设备上增强计算能力,来优化数据密集型场景的IO负担,试图在大数据和企业高性能存储场景拓宽市场。但一直没有规模化的市场推动,SanDisk 结合ANN在大容量索引场景计算型存储构想,拓宽了行业内对计算型存储的认知。
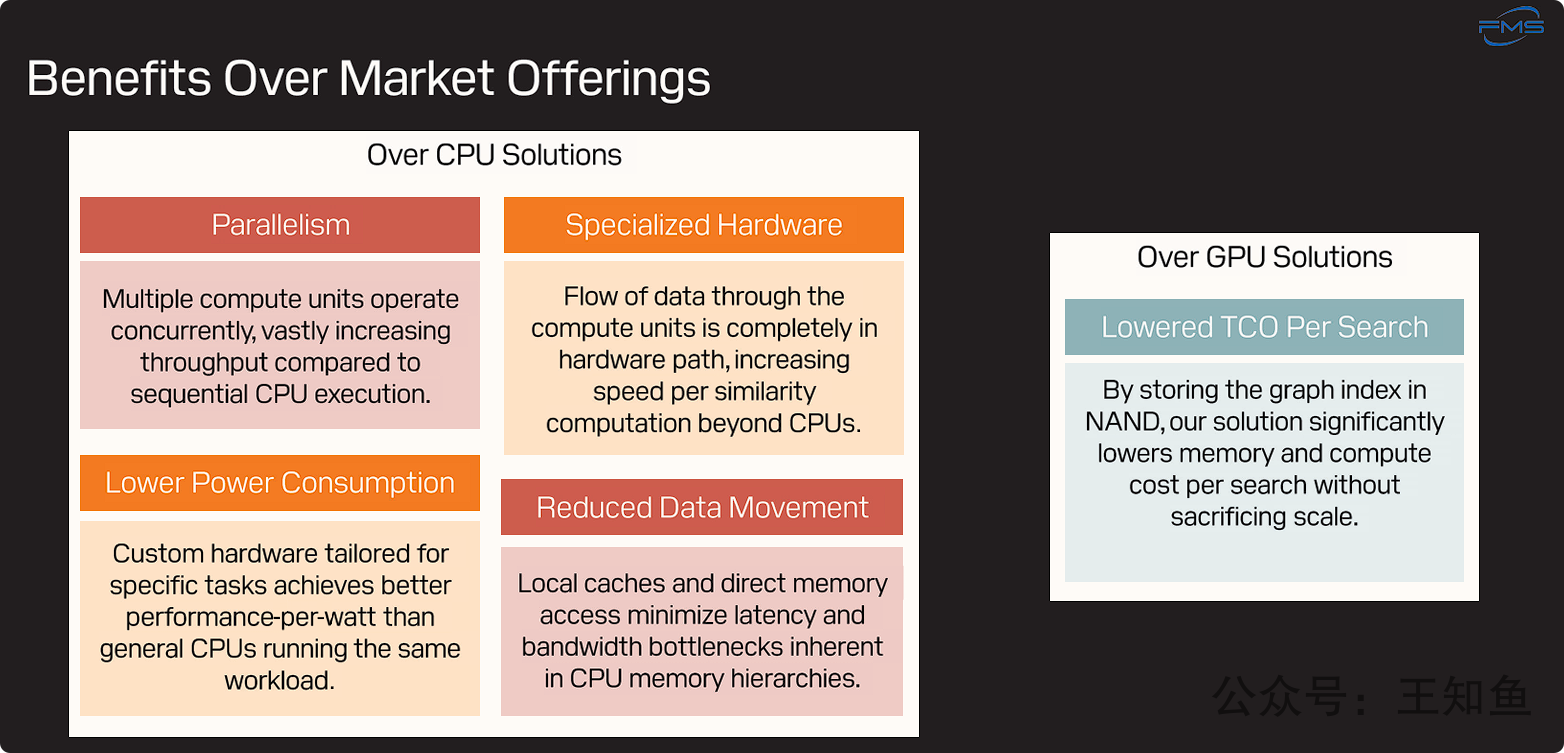
左侧区域:相比CPU方案的优势
| 优势 | 描述 | 解释 |
|---|---|---|
| Parallelism (并行性) | “多个计算单元并发运行,与CPU的顺序执行相比,极大地提升了吞吐量。” | SanDisk的设备内置了大量并行的专用计算单元,可以同时处理多个计算任务。而CPU虽然有多核,但在处理这类负载时,其并行效率和规模远不及这种专用硬件设计,因此SanDisk方案的查询吞吐量(QPS)会高得多。 |
| Specialized Hardware (专用硬件) | “数据流在计算单元中完全通过硬件路径处理,其相似度计算的速度超越了CPU。” | 向量的距离计算等核心操作是由固化的硬件电路(ASIC或FPGA)来执行的,而非在通用CPU上运行软件指令。这种硬件化的执行路径消除了软件开销,使得单次计算的速度和效率远超通用处理器。 |
| Lower Power Consumption (更低功耗) | “为特定任务量身定制的硬件,在运行相同工作负载时,比通用CPU实现了更高的每瓦性能(performance-per-watt)。” | 专用硬件只做一件事,并为此进行了极致优化,因此其能源效率非常高。相比之下,通用CPU为了处理各种任务而设计得非常复杂和耗电。在向量搜索这个特定场景下,SanDisk的方案能用更少的电力完成更多的工作,这直接关系到数据中心的运营成本(电费和散热)。 |
| Reduced Data Movement (减少数据移动) | “本地缓存和直接内存访问(DMA)最大限度地减少了CPU内存体系中固有的延迟和带宽瓶颈。” | 这是计算存储架构的核心优势。通过在存储设备内部进行计算,避免了数据从SSD经过PCIe总线传输到系统DRAM,再加载到CPU缓存的漫长路径。数据移动的距离被大大缩短,从而显著降低了延迟,并减少了对系统总线带宽的占用。 |
右侧区域:相比GPU方案的优势
| 标题 | 描述 | 解释 |
|---|---|---|
| 降低单次搜索的总拥有成本 | “通过将图索引存储在NAND中,我们的解决方案在不牺牲扩展性的前提下,显著降低了单次搜索的内存和计算成本。” | 这是最关键的商业价值主张。GPU方案的致命弱点是要求整个索引必须放入昂贵且容量有限的GPU显存(VRAM)中。SanDisk的方案将索引主体存放在成本极低、容量巨大的NAND闪存上。这意味着用户可以用远低于购买高端GPU的成本来部署能够支持海量数据集的向量搜索系统,从而极大地降低了总拥有成本(TCO),同时还能轻松扩展到更大的数据规模。 |

-
ANN 最近邻搜索 在AI/ML 、大模型RAG应用、推荐算法和语义搜索领域非常重要
-
图搜索凭借其准确、稳定和高效在ANN众多算法中处于领先地位
- Nvidia Cuda 增强的ANN 算法有最高效率,但对HBM要求高,落地成本高昂
- 微软基于 DiskANN 的实践,能解决索引对存储容量的需求,但时延高
-
SanDisk 提出一种结合上述两方案优势的计算性存储方案,用于增强图搜索过程的性能
- 通过将索引从昂贵的内存(DRAM/VRAM)转移到NAND上存储,显著降低了单次搜索的总拥有成本
- 通过专用的硬件加速器,实现了比通用CPU更高的并行度和吞吐量
- 提供了更优的可扩展性(轻松支持更大规模数据集)和整体效率(更高的每瓦性能)
-
计划将硬件加速能力从当前的“索引搜索”阶段,进一步扩展到对“索引构建”算法的支持。索引构建本身也是一个计算和I/O密集型的过程,加速这一过程将为用户提供一个完整的端到端加速解决方案。