
AI大模型时代:高性能数据湖与存储架构的破局之道
问题意识
High Performance Data Lakes and Lakehouses for AI
Wendell Wenjen
1. 背景介绍
在AI大模型浪潮席卷全球的今天,所有目光都聚焦在模型效果和应用创新上。然而,作为解决方案架构师,我们深知高质量AI的基石在于高质量的数据基础设施。一个现代AI数据管道绝非简单的线性流程,而是一个从数据采集、精炼、训练到推理部署的动态闭环系统,它对计算资源(CPU/GPU)和存储性能提出了极端的异构需求。
您的企业是否正面临以下挑战: 如何构建一个能够高效支撑从海量原始数据(10PB级)到高度优化模型(GB级),再到庞大日志输出(10PB级)的动态存储架构?本文将深入分析AI数据管道对存储容量和性能的独特需求,探讨现代数据湖如何从传统模式演进为高性能、分层的Data Lakehouse,并为您提供在企业级AI应用落地中,优化存储效率和构建Agent记忆体的核心洞察。
2. 阅读收获
- 掌握AI数据管道的存储需求异构性:
- 理解AI工作流(ETL、训练、推理)对存储容量的 “两头大、中间小” 特征,指导设计分层存储架构,避免资源浪费。
- 识别数据精炼依赖CPU、模型训练依赖GPU的异构计算需求,并将其映射到高性能(Flash)和容量优化(HDD)的存储层。
- 洞察现代数据湖的架构演进:
- 理解现代数据湖如何通过对象存储作为基础,并集成全闪存系统,从传统Hadoop模式转向高性能、统一的Data Lakehouse架构。
- 了解VAST Data等存储ISV在高性能文件存储和数据湖仓领域的市场定位和技术优势。
- 聚焦企业AI落地的核心任务:
- 明确对于非平台型企业,核心任务是构建高效推理基础设施和Agent记忆体(如向量数据库)的存储优化,而非盲目追求高门槛的模型微调。
3. 开放性问题
- Data Lakehouse的融合挑战: 随着VAST等高性能存储ISV向Data Lakehouse架构演进,将数据库、文件和对象存储功能融合,您认为这对传统云厂商提供的独立数据湖服务(如对象存储+HDFS)会带来哪些颠覆性挑战和合作机遇?
- Agent记忆体的存储治理: 随着Agent工具链的成熟,其“记忆体”存储(如向量数据库、KV缓存)在性能、数据一致性和企业级治理方面,应如何与现有企业数据平台(如Data Lake)进行高效、可信赖的整合?
- 成本与性能的平衡艺术: 在实际企业AI应用中,如何通过精细化的数据分层策略,平衡高性能(Flash)和容量成本(HDD),设计出最经济高效、且能满足SLA的AI数据湖分层架构?
👉 划线高亮 观点批注
Main

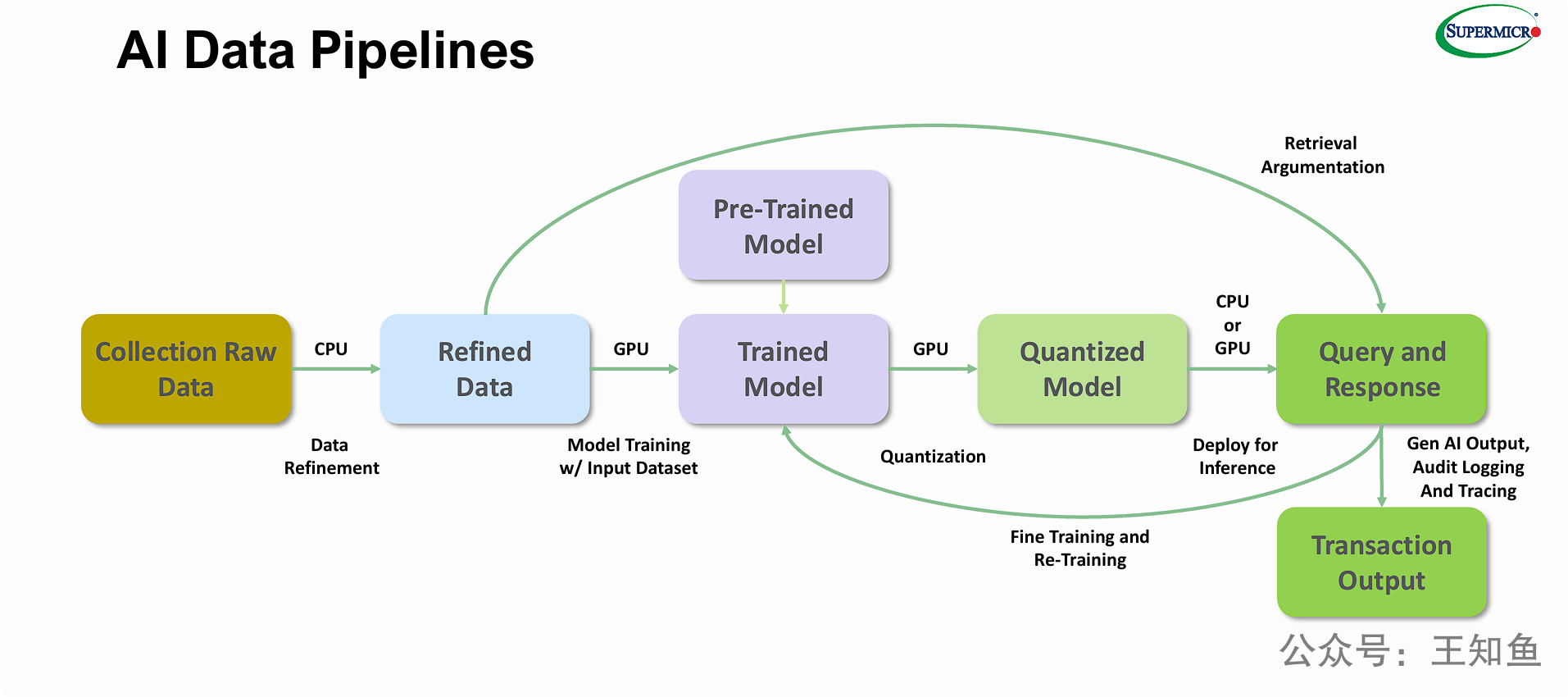
PPT 旨在说明一个现代 AI 数据管道是一个动态且闭环的系统,而不仅仅是一个线性的流程。其核心观点包括:
-
AI 流水线的全生命周期: 图片清晰地展示了从数据采集、数据精炼、模型训练、模型量化、推理部署到最终输出的完整AI工作流。
-
异构计算的需求: 它明确指出了不同阶段对计算资源的特定需求:数据精炼(ETL)依赖 CPU,而模型训练和量化则严重依赖 GPU,推理阶段则可以灵活选择 CPU 或 GPU。
-
持续改进的闭环系统: 最关键的信息是两个反馈循环。这表明 AI 系统不是一次性构建的,而是通过 MLOps("微调与重新训练"循环)和数据增强("检索增强"循环)不断迭代和优化的。生产数据被反馈回训练和数据精炼阶段,实现模型的持续学习和知识更新。
-
(隐含的存储意义): 作为一个 AI 数据管道,这张图隐含了对多层存储架构的需求:需要大容量存储来“收集原始数据”;需要高性能、高吞吐的存储(如并行文件系统或高速闪存)来支撑 "Refined Data" 被 GPU 集群高速读取以进行“模型训练”;还需要快速的存储来加载 "Quantized Model" 并处理 "Query and Response" 阶段的日志和追踪数据。
昨天和国内头部云厂商的存储架构师漫聊,随着高质量模型开源,业内做训练的门槛越来越高,玩家越来越集中,但并不代表模型训练就不再重要,而是目光被媒体和行业拉扯到应用侧,而应用侧面临的问题,其实比模型训练还要复杂。高质量模型一定是基于高质量数据产生的,而后者要参考上述精炼的过程,如何构建完备的大数据基础设施,是企业AI决策者不可忽视的。

AI数据管道在功能上实现了从“非结构化”数据到“结构化”输出的转变,而这种转变在物理架构上需要一个多层化、专业化的存储系统来支持。
-
AI的本质是数据形态的转换: AI管道的核心价值是将杂乱的非结构化数据(如原始文本、日志)转化为结构化的智能响应和数据(如Gen AI输出、审计日志)。
-
AI需要分层的存储架构: 幻灯片通过具象化的存储图标,清晰地指出了AI工作流的每个阶段都需要不同特性和类型的存储解决方案。
-
具体存储组件的映射: 它明确了AI管道所需的五种关键存储/内存组件:
-
数据湖 (Data Lake): 应对海量原始数据。
-
精炼数据存储 (Refined Data): 应对高性能训练数据读取。
-
模型仓库 (Trained Models): 应对模型版本和管理。
-
RAG 数据存储 (RAG Data): 应对(如向量数据库)知识库的实时检索。
-
KV 缓存 (KV cache): 应对(如高速内存)推理时的高速读写缓存。
-
前面提到大数据基础设施,对于非平台型企业来说,通常是不具备完整的数据管道的,而传统大数据基础设施面向海量数据源的架构,对于企业来说也无法契合,因此可以看到,越来越多的头部数据库厂商(Oracle、Maria DB等),正在参与整合企业侧的数据管道,通过从长期使用的关系型数据库向数仓转型,同时耦合AI应用的高性能检索/存储,来满足企业的AI应用需求。


AI数据管道的不同阶段对存储容量的需求差异极大,呈现出“两头大、中间小”的特征,因此必须使用专门构建的(Purpose-Built)存储平台来匹配每个阶段的特定需求。
-
存储容量需求的不均衡性: AI工作流不是一个对存储容量有统一需求的平台。数据入口(原始数据湖)和数据出口(日志与输出)需要海量的PB级容量。
-
数据价值链中的容量变化: 随着数据在管道中流动,其形态和容量发生剧烈变化:
-
原始数据(10PB级): 海量、低价值密度。
-
精炼数据/模型(PB级): 经过处理,容量减少,但价值密度提高。
-
可部署模型(TB/GB级): 高度优化,容量小,价值密度极高。
-
输出与日志(KB到10PB级): 单次输出小(KB),但总量随时间累积极为庞大。
-
-
“专门构建的存储平台”的必要性(副标题): 鉴于这种从 10PB 到 GB 再回到 10PB 的巨大动态范围,使用单一类型的存储(例如,全部使用昂贵的高性能存储或全部使用廉价的归档存储)是低效且昂贵的。一个优化的AI存储架构必须是分层的、异构的,为管道的每个阶段(如海量数据湖、高性能训练、低延迟推理、日志聚合)提供专门优化的存储解决方案。
AI管道的不同阶段对存储性能指标需求不一致,应该已经形成共识,对于试图在企业应用AI的IT管理者来说,其实并不需要构建一个完整的AI管道,因为不是所有企业都有能力、需求去构建私有模型,要警惕动辄忽悠客户做模型微调的AI解决方案,因为没有这个必要。对于应用侧来说,最重要的还是高效推理基础设施,以及Agent 工具链成熟后的记忆体构建,对于存储解决方案供应商来说,如何优化、整合好这两个场景的存储效率,是满足未来企业级存储平台的核心任务。

现代数据湖不再是单一的、同质化的存储池,而是一个分层的、异构的架构,旨在平衡性能和容量成本。
-
数据湖的定义: 它的核心功能是作为所有原始数据(结构化和非结构化)的单一汇聚点,以供未来处理。
-
两层架构(热/冷分层): 这是本图的关键。现代数据湖被分为:
-
高性能层 (Hot Tier): 占10-20%容量,通常由 Flash(闪存) 实现,服务于AI、HPC等高性能计算和分析工作负载。
-
容量优化层 (Cold Tier): 占80-90%容量,通常由 HDD(硬盘) 实现,支持对象、文件、HDFS等多种协议,用于海量数据的经济型存储。
-
-
广泛的兼容性: 数据湖需要能够从各种来源(传统应用、微服务)摄入数据,并为各种高性能消费者(GPU服务器、HPC集群)提供数据服务。
对于服务器OEM厂商来说,超威从硬件集成跨界到数据湖的软件侧,站在业务角度思考场景需求,是解决方案必须构建起的能力,否则方案对客户不敏感,无法引起共鸣。

现代数据湖架构正在从基于HDD、复杂且孤立的传统模式,演变为基于对象存储、可无缝集成且性能更强的平台。
-
传统架构的痛点: 传统数据湖(特别是Hadoop)和数据仓库存在数据孤岛、管理复杂和模式僵化的问题。
-
现代架构的优势: 现代数据湖利用对象存储作为基础,实现了高可扩展性,并打破了数据孤岛,能够“无缝集成”各种数据源和应用。
-
统一平台: 现代数据湖是一个统一的平台,可以同时处理从备份、物联网到AI训练等多种数据输入,并支撑从金融交易、OLTP到AI数据准备等多种应用。
-
存储基础的演进: 这是本图的关键技术点。它明确指出,虽然传统数据湖依赖HDD,但为了满足AI、实时分析等“新用途”的性能需求,现代数据湖正在通过增加全闪存系统(All-Flash systems) 来进行性能增强,这与上一张PPT中“高性能数据湖”层的概念完全一致。
对于平台型企业来说,传统数据湖的架构仍然有其应用场景,如AI管道的数据精炼过程,早期基于HDD+多级缓存/中间件构建起来的服务链条对于综合型场景来说,比单纯提供全闪存系统来说,起码经过实践检验。


-
架构分类是关键: 本图最重要的信息是将数据湖解决方案分为三类:
-
对象存储 (Object Storage): 对应前几张PPT中的“容量优化层”(冷层/海量层)。
-
带对象分层的文件存储 (File with Object Tier): 对应“高性能数据湖层”(热层/性能层),这些系统(如VAST, WEKA)是专为AI/HPC设计的高性能文件系统,并集成了到对象存储的自动分层。
-
数据湖仓 (Data Lakehouse): 代表了最新的行业趋势,将数据库(如EDB Postgres)和数据湖平台(如VAST)的功能融合,以统一处理分析和AI。
-
-
VAST的特殊地位: VAST Data 被同时列在 “文件存储” 和 “数据湖仓” 两类中,这凸显了它作为高性能文件平台,并正向统一的数据湖仓架构演进的市场定位。
对于企业侧AI场景落地,IT决策者要了解不同存储ISV的核心优势和差异化场景的能力,这对于未来企业AI应用落地的健壮性和可持续性有深远影响,尤其是在存储越来越独立的AI应用场景。