
量子计算崛起:存储技术的新挑战与机遇
问题意识
Quantum Computing - Memory & Storage directions & requirements
Jung H. Yoon
Distinguished Engineer & CTO
背景介绍
量子计算正从实验室走向现实应用,但其真正的潜力发挥不仅依赖于量子比特的突破,更取决于底层数据基础设施的支撑能力。与传统计算相比,量子计算机凭借叠加态和纠缠态特性,能够进行并发计算和复杂运算,这种超凡能力对内存和存储系统提出了前所未有的要求。
当前量子计算实践严重依赖经典存储设备,形成了独特的量子-经典混合架构。从量子比特的短暂寄存器到经典高速内存,再到持久化存储,每一层都面临着退相干、稳定性、纠错和读出等核心挑战。随着量子计算与HPC、AI的深度融合,构建统一的全局数据平台成为支撑未来"以量子为中心的超级计算"架构的关键。
您是否曾思考过,当量子计算真正普及时,我们的存储系统将如何应对这种范式转变?本文将带您深入探索这一前沿话题。
读者收获要点
- 掌握量子计算对存储系统的独特需求:理解量子比特特性如何从根本上改变数据存储的容量和性能要求
- 了解当前混合存储架构实践:认识分层存储方案如何解决量子信息的临时存储与持久化问题
- 把握量子存储技术前沿进展:熟悉晶体缺陷、自旋存储等新兴研究方向及其应用价值
- 预见未来存储基础设施演进:洞察统一数据平台在异构计算环境中的核心作用
开放性问题
-
在当前技术条件下,量子计算的数据存储瓶颈更多来自于量子态本身的脆弱性,还是经典存储系统的性能限制?未来突破的关键路径是什么?
-
随着量子计算与经典HPC的深度融合,存储系统需要同时满足量子计算的海量数据处理需求和经典计算的高性能要求,这种异构存储架构将如何演进?
-
量子启发算法已经在优化经典数据存储方面展现出潜力,这类技术能否成为量子计算实用化之前的过渡方案?它们对传统存储技术的改进空间有多大?
👉 划线高亮 观点批注
Main

PPT的核心观点是:量子计算的实现和普及,不仅仅是计算本身的突破,更是对底层数据基础设施(即内存与存储系统)的巨大挑战。
它通过以下逻辑链条传达这一信息:
-
前提: 量子计算拥有远超传统计算的超凡数据处理能力。
-
依赖: 这种能力的发挥,严重依赖于一个能够支持其“访问、分析和存储”海量数据的高性能、大容量的数据底座。
-
引申: 因此,对于存储行业而言,量子计算时代的到来意味着必须发展全新的内存和存储技术,以满足这一前所未有的需求。这张PPT旨在引出“量子计算对存储提出新要求”这一核心议题。

量子计算核心原理的入门介绍,其主要目的有两个:
-
科普核心概念: 为不熟悉量子领域的观众(特别是存储行业的专业人士)清晰地定义了量子计算的三大基石:量子比特 (Qubit)、叠加态 (Superposition) 和 纠缠态 (Entanglement)。它通过与传统比特的对比和布洛赫球面的图示,让这些抽象概念更易于理解。
-
点明存储挑战: 在介绍这些强大原理的同时,PPT巧妙地指出了它们给存储技术带来的直接挑战。
-
容量挑战: 量子比特的叠加态特性,意味着要表示和存储一个量子系统的状态,需要比传统方式大得多的信息量。
-
稳定性挑战: 现有的量子存储技术存在“保持时间短”和“易出错”的致命弱点,这对于构建可靠、持久的量子存储系统是巨大的技术障碍。
-
===
核心概念定义:
-
Qubits (量子比特):
-
文字解释: 对比了传统比特(只能是0或1)和量子比特。量子比特可以同时处于0和1的叠加态,这极大地增加了对存储容量的需求。
-
图示解释: 左侧的“Classical Bit”(经典比特)用两个独立的点形象地表示了它只能是0“或”1。右侧的“Qubit”(量子比特)使用了一个布洛赫球面 (Bloch Sphere) 来表示。球的北极点代表状态 ∣0⟩,南极点代表状态 ∣1⟩,而球面上的任意一点都代表一个可能的叠加态。这直观地展示了量子比特可以表示远比0和1丰富得多的信息状态。
-
-
Superposition (叠加态):
- 文字解释: 定义为一种量子现象,即一个量子比特可以一次处于多种状态的叠加。这种特性使得量子计算机能够进行并发计算 (concurrent computations)。
-
Entanglement (纠缠态):
- 文字解释: 定义为一种量子现象,即两个或多个量子比特变得相互关联,无论它们相距多远,一个的状态会瞬间影响另一个。这种特性是实现复杂计算 (complex computations) 的关键。

PPT旨在全面概述量子存储领域的现状,传达了两个核心观点:
-
研究方向多样化,潜力巨大: 量子存储的研究正在多个前沿方向上积极推进,包括利用晶体缺陷、电子自旋和光子等物理现象的硬件技术,以及能够先行应用于经典计算的量子启发算法。这些研究方向预示着未来存储在密度、速度和能效上的巨大潜力。
-
基础性挑战严峻,亟待突破: 尽管前景广阔,但量子存储技术面临着源于量子力学本质的四大根本性挑战:退相干(信息易失)、稳定性(寿命极短)、纠错(机制复杂)和读出(测量即破坏)。这些问题是当前阻碍实用化量子存储发展的关键瓶颈,必须从基础科学和工程技术上取得突破。
===
第一部分:量子存储研究 (Quantum Memory Research)
这部分列举了当前几种有前景的量子存储研究方法:
-
Crystal Defects (晶体缺陷): 这种技术利用晶体结构内的单个原子缺陷来存储TB级别的经典数据。它旨在通过在原子层面操控物质来存储信息。
-
Spin-based storage (基于自旋的存储): 该技术利用电子的自旋(spin)状态来存储数据。其潜在优势在于能实现更高的存储密度和更快的数据读取速率。
-
Quantum Photonic Devices (量子光子器件): 使用光子与物质的相互作用 (photon interaction) 来使量子比特能同时存在于多个能量状态。这项技术的优势在于能实现更快的数据处理和存储,并有望发展出高效、低功耗的纳米级半导体技术。
-
Quantum Inspired Algorithms (量子启发算法): 这是一种算法层面的研究,旨在通过改进数据检索速度和优化存储来增强经典的(非量子的)数据处理。它被应用于优化数据压缩,并有望提供比传统方法更优越的压缩率。
第二部分:量子存储技术的挑战 (Challenges of Quantum Memory technology)
这部分指出了实现可靠量子存储所面临的四个核心技术障碍:
-
Decoherence (退相干): 这是最核心的挑战之一。量子比特非常脆弱,容易受到环境噪声的干扰,导致其量子态丢失(即退相干),从而引发错误。PPT特别指出,当试图将量子计算数据引入现有的数据存储框架时,会发生退相干,导致量子态丢失、数据损坏和数据丢失。
-
Stability (稳定性): 构建具有稳定、可靠量子存储的大规模量子计算机是一项重大的技术挑战。PPT指出,量子力学比特(Quantum mechanical bits)无法长时间存储,它们会在很短的时间(毫秒级)内衰减和坍塌。
-
Error Correction (纠错): 由于退相干和其他错误的影响,量子计算需要非常复杂精密的纠错技术来对其进行缓解。这远比传统计算中的纠错机制要困难。
-
Readout (读出): 读取存储在量子比特中的信息本身就具有挑战性,并且这个读取过程本身可能就会破坏其量子态。这意味着读取一次数据后,原始的量子信息可能就消失了。
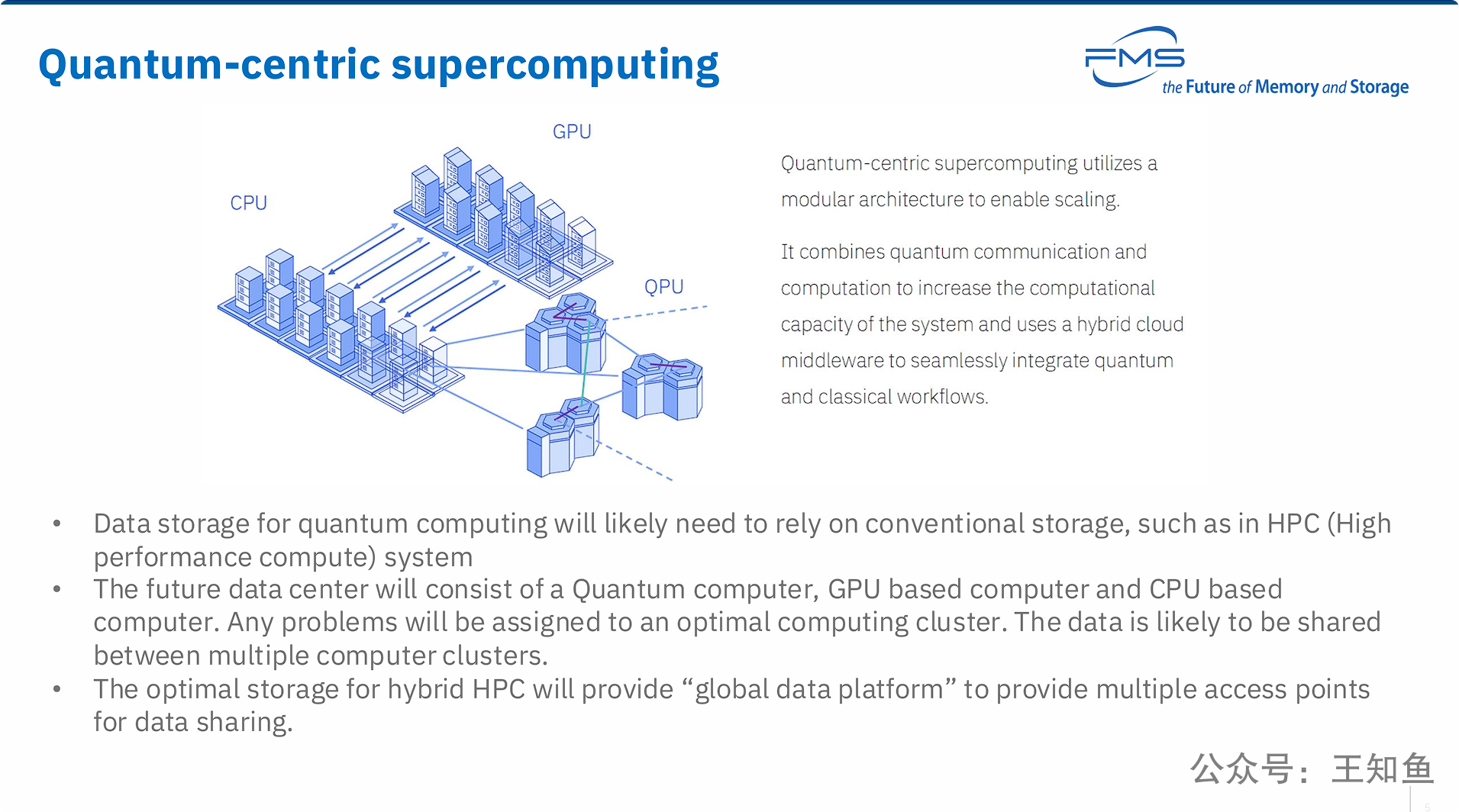
PPT的核心观点是,量子计算的未来并非孤立发展,而是深度融入经典高性能计算(HPC)生态,形成一个统一的、异构的“以量子为中心的超级计算”架构。
-
架构融合: 未来的超算系统是一种融合架构,其中QPU(量子处理单元)将与CPU和GPU一样,作为一种处理特定任务的专用加速器或协处理器。
-
工作流协同: 解决复杂问题将不再依赖单一计算模式,而是通过一个智能的中间件,将一个大任务拆解,把不同部分交给最擅长的计算单元(CPU、GPU或QPU)处理,实现混合工作流。
-
存储是基石: 在这个异构体系中,存储扮演着至关重要的“统一数据底座”的角色。为了让CPU、GPU和QPU高效协同,必须有一个所有计算单元都能高速访问的 “全局数据平台” 。这个平台打破了数据孤岛,确保了在不同计算范式之间流转和共享数据时的高效性和一致性,是整个“量子为中心的超算”架构得以实现的关键基础设施。
计算范式区分 CPU、GPU和QPU,服务三大计算系统的存储系统需要是统一的,这预示着对于大型计算研究机构,统一、高性能的数据平台将成为计算系统设计的默认前提。
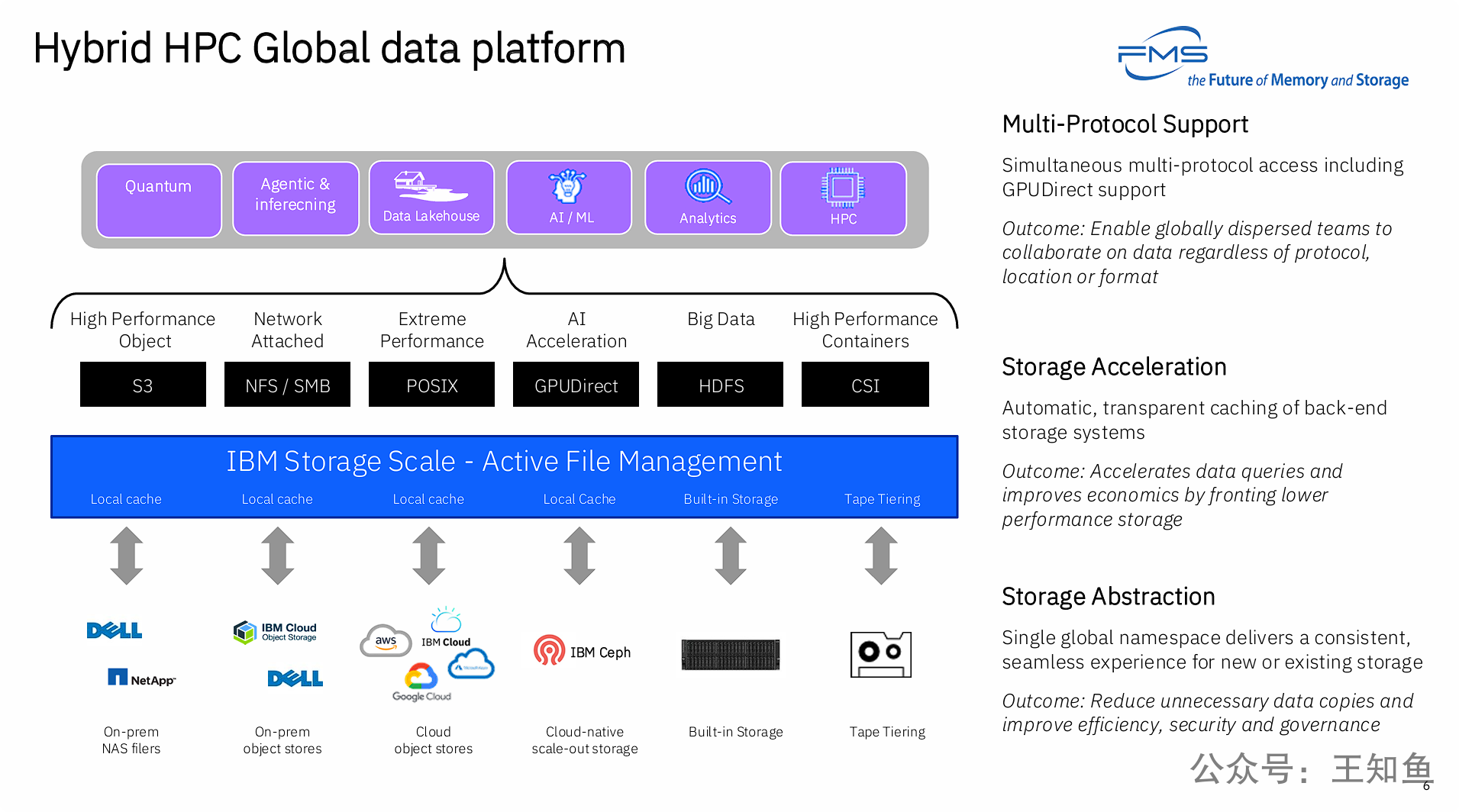
PPT的核心观点是:要实现上一页提出的“以量子为中心的超级计算”架构,必须采用一个先进的、软件定义的“全局数据平台”,而IBM Storage Scale正是这样一个解决方案。
这张PPT通过一个具体的产品实例,雄辩地论证了理想的存储平台需要具备三大核心能力,以应对HPC、AI和量子计算融合带来的挑战:
-
统一性 (Unity): 通过存储抽象和单一全局命名空间,将底层异构、分散的物理存储(无论在本地还是云端)整合成一个逻辑上的单一数据池,从根本上简化数据管理。
-
通用性 (Universality): 通过多协议支持,让上层多样化的应用(从HPC到AI再到量子)都能以最高效、最原生的方式访问同一个数据副本,消除数据孤岛和因协议不通而导致的数据迁移。
-
智能性 (Intelligence): 通过存储加速(自动缓存与分层),根据数据访问的热度智能地在不同性能和成本的存储介质间移动数据,以最优的成本提供最高的性能。

面对量子计算带来的数据挑战,我们短期内不能指望纯粹的量子存储技术取得突破;相反,行业发展的现实路径是构建一个融合了量子、GPU和CPU的混合高性能计算(HPC)架构。而支撑这一未来架构的关键,在于打造一个先进的、以软件定义的“全局数据平台”,以此作为统一的数据底座,来满足异构计算环境下无缝、高效的数据共享需求。
目前量子计算实践领域的存储方案是如何实现的?
目前还没有商用化的、能够像SSD或内存一样直接存储量子比特(Qubits)的持久化“量子硬盘”或“量子RAM”。所有的数据存储,无论是输入、中间过程还是最终结果,都严重依赖并实现在经典存储设备上。
下面我将详细解释这个混合架构是如何实现的,可以将其理解为一个分层模型:
量子-经典混合存储分层架构 (Quantum-Classical Hybrid Storage Hierarchy)
第一层:量子比特本身 (量子态的“寄存器”)
这是唯一真正进行“量子信息存储”的地方,但它极其短暂且脆弱。
-
实现方式: 通过超导电路、离子阱、光子等物理系统来维持量子比特的叠加态和纠缠态。
-
功能: 类似于经典计算机中的CPU寄存器。它们在算法计算过程当中临时“存储”量子信息。一个量子算法的运行,就是对这些量子比特进行一系列的逻辑门操作。
-
局限性: 这正是PPT中提到的 “退相干 (Decoherence)” 和 “稳定性 (Stability)” 挑战的直接体现。量子态的寿命极短(通常在微秒到毫秒之间),只能用于计算,完全无法用于持久化存储。一旦计算结束或发生退相干,信息就丢失了。
第二层:经典控制和测量系统 (高速I/O接口)
这一层是连接脆弱的量子世界和稳固的经典世界的桥梁。
-
实现方式: 由精密的电子设备(如FPGA、任意波形发生器等)组成,它们将经典的指令(例如,要执行哪个量子门)转换为具体的物理信号(如微波脉冲、激光)来操控量子比特。
-
功能:
-
写入: 将经典计算机准备好的算法步骤(量子电路)“写入”到量子比特上。
-
读出 (Readout): 当计算完成后,对量子比特进行测量。这个测量过程会导致量子态坍缩成确定的经典状态(0或1)。测量系统捕获这些经典结果。这直接对应PPT中提到的“读出”挑战,即测量过程本身会破坏量子态。
-
-
存储角色: 这一层不存储数据,但它是数据流入和流出的必经通道,将量子信息转化为经典信息。
第三层:经典高速内存 (实时“热”数据层)
测量出的经典数据需要被立即捕获和处理。
-
实现方式: 高速的经典RAM,通常物理上非常靠近量子处理器,以减少延迟。
-
功能: 这是许多变分算法 (Variational Algorithms) 或需要迭代的量子算法的关键。
-
存储中间结果: 量子计算运行一次(一次“shot”)的结果(一串0和1)被存储在这里。
-
支持纠错: PPT中提到的 “纠错 (Error Correction)” 也依赖这一层。系统需要快速读出辅助比特的状态,用经典逻辑判断是否出错,然后迅速反馈操作来纠正错误。
-
迭代优化: 在VQE等算法中,量子程序运行得出结果,经典计算机(利用RAM中的数据)对结果进行分析,调整下一轮量子程序的参数,然后再次运行。这个“量子-经典”循环需要高速内存来支持。
-
第四层:经典高性能存储 (程序与结果的“温/冷”数据层)
这是我们通常理解的“存储”,负责所有持久化的数据。
-
实现方式: 高性能SSD、硬盘阵列、甚至是连接到云端或本地HPC集群的并行文件系统。
-
功能:
-
存储输入数据: 运行量子算法所需解决的初始问题和参数,完全以经典数据形式存储。
-
存储量子程序: 描述整个量子算法的“量子电路”本身,也是以经典文件的形式存储。
-
存储最终结果: 量子计算机通常需要运行成千上万次来对结果进行统计平均,以获得一个概率分布。这些海量的、经典的测量结果(0和1的字符串)被汇总后,最终的统计结果会存储在硬盘或SSD上。
-
存储校准和日志数据: 维持量子计算机稳定运行需要天量的校准、调试和环境监控数据,这些数据也全部存储在经典存储设备上。
-
总结
所以,当一个研究员今天在实践中使用一台量子计算机时,他的工作流是这样的:
-
在经典计算机上编写代码,定义问题和量子算法。
-
这些数据通过网络传输,被加载到控制系统的经典存储中。
-
控制系统将算法指令转换为物理信号,在量子比特(QPU)上执行计算。
-
计算结果被测量,转换为经典比特流。
-
这些比特流被经典高速内存捕获,可能用于实时反馈或迭代。
-
经过成千上万次运行后,最终的统计结果和所有日志数据被永久保存在经典硬盘或SSD上,供研究员后续分析。
PPT中提到的“量子存储研究”(如晶体缺陷、自旋存储)正是为了尝试突破目前这种依赖经典存储的模式,但它们距离成为实践方案,还有非常长的路要走。