
SuperMicro:基于Grace CPU 、DPU的存储方案
问题意识
High Performance Storage for the Data Center
Paul McLeod
OEM 存储方案,我们应该期待什么?
材料重点介绍了 超微 最新适配 NVIDIA Grace CPU、BlueField DPU 的存储解决方案,作为紧贴 NVIDIA GPU生态的全栈存储方案。
👉 划线高亮 观点批注
Main

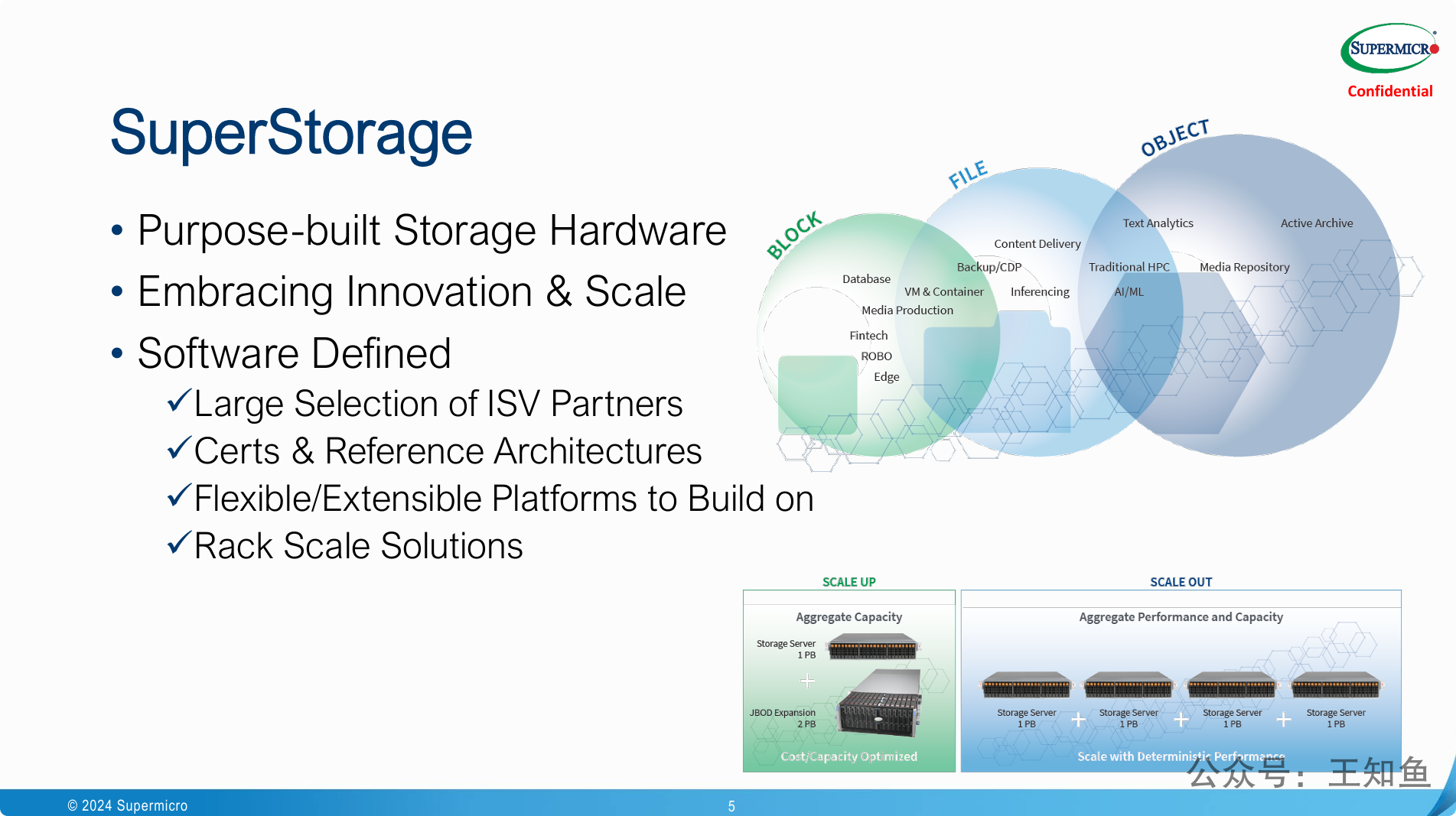
图中右上角对三类常见存储资源的使用场景划分值得参考。
尽管业界基于对象存储的网关应用越来越多,加 iscsi 网关构成 块存储服务,加 NFS/Samba 网关构建文件存储,但不同存储形态与生俱来就有场景差异,为了缓解成本(普遍印象里对象存储成本低,其实不低),而做协议切换,往往对系统IO稳定性带来巨大挑战。
选择适合的,少折腾,才是对系统应用负责。
图下方介绍了存储扩容常见的两个概念:SCALE UP 和 SCALE OUT,稍作对比,以增强理解:
1. SCALE UP (垂直扩容)
- 概念: SCALE UP,也称为垂直扩容,是指通过增加单个存储设备(如服务器或存储阵列)的资源来提升其性能和容量。你可以把它想象成给一台电脑升级配置。
- 具体操作:
- 增加硬盘数量或更换更大容量的硬盘。
- 增加内存(RAM)。
- 升级更快的处理器(CPU)。
- 增加更高速的网络接口卡(NIC)。
- 优点:
- 管理相对简单,因为你只管理一个或少数几个设备。
- 通常性能提升更直接,因为所有资源都在一个物理设备上。
- 缺点:
- 存在硬件上限,单个设备的资源是有限的,不可能无限扩容。
- 成本较高,高端硬件通常更昂贵。
- 单点故障风险,如果这个设备出现问题,整个存储系统可能会受影响。
- 扩容时可能需要停机。
2. SCALE OUT (水平扩容)
- 概念: SCALE OUT,也称为水平扩容,是指通过增加更多的存储设备(服务器或存储节点)来共同分担负载和增加总容量。你可以把它想象成增加更多的电脑来组成一个集群。
- 具体操作:
- 添加更多的存储服务器或存储节点到一个集群中。
- 通过分布式文件系统或对象存储系统将这些节点连接起来,使其作为一个统一的存储资源对外提供服务。
- 优点:
- 几乎可以无限扩容,只要不断添加新节点即可。
- 高可用性,即使部分节点出现故障,整个系统仍然可以继续运行(通过数据冗余和故障转移机制)。
- 成本效益更高,可以使用标准化的、相对便宜的硬件。
- 通常可以在线扩容,无需停机。
- 缺点:
- 管理复杂性增加,需要管理更多的设备和分布式系统。
- 数据一致性和同步可能成为挑战。
- 需要专门的软件(如分布式文件系统、对象存储软件)来协调和管理这些节点。
总结对比
| 特性 | SCALE UP (垂直扩容) | SCALE OUT (水平扩容) |
|---|---|---|
| 方式 | 增加单个设备的资源 | 增加更多设备 |
| 上限 | 硬件限制,有上限 | 理论上无上限 |
| 成本 | 高端硬件成本高 | 标准化硬件成本相对低 |
| 管理 | 相对简单 | 相对复杂 |
| 可用性 | 单点故障风险高 | 高可用性,容错性好 |
| 扩容 | 可能需要停机 | 通常可以在线扩容 |
在现代云计算和大数据环境中,SCALE OUT 策略因其灵活性、高可用性和成本效益而越来越受欢迎。然而,SCALE UP 在某些特定场景下(例如需要极致单机性能或管理简单性)仍然有其价值。

左侧3个属于HDD整机产品,从左到右依次区分为:企业级、云服务商高密型(顶开盖式)和通用型
- 企业级区分2U/3U/4U,可容纳16-36 个3.5英寸大硬盘 (LFF Bays)
- 云服务高密型,主要是4U机型,最高可容纳 90个硬盘
- 通用的2U型,有24个机械盘位+4个 NVMe SSD 缓存盘
右侧2个属于全闪SSD存储,区分高可用双端口(控制器)和极致性能型
-
这里提到的全共享架构 (Shared Everything Architecture) 和 VAST 的软件实现是两个不同概念,是指:
-
两个控制器都连接到同一个背板 (Backplane) 上,而机箱前方的所有24个NVMe SSD都插在这个背板上。
-
这就实现了“共享”:无论哪个控制器,都可以通过共享背板访问到全部24个硬盘。它们还共享同一个机箱、电源和风扇等基础资源。
-
展示Supermicro公司全面的存储产品线布局,该布局通过两大类产品满足了市场的不同需求:
-
容量密集型存储: 以传统的3.5英寸硬盘为基础,通过 ENTERPRISE、TOP LOADING、SIMPLY DOUBLE 等系列,在不同的机箱尺寸(2U到4U)和架构下,为云服务商和企业数据中心提供了追求最大存储容量和最低每TB成本的解决方案。
-
性能密集型存储: 以全闪存(All-Flash)为核心,通过 HIGH AVAILABILITY DUAL-PORT 和 PETASCALE ALL-FLASH 两个系列,专注于提供极致的性能(高IOPS和带宽)、高可用性(双控架构)和高密度。这些产品利用了最新的NVMe和EDSFF等闪存技术,旨在为关键业务应用和大规模数据处理场景提供优化的总体拥有成本(TCO)。

-
完全冗余的系统设计: 产品的核心是 “无单点故障” 。从双热插拔控制器,到双端口NVMe硬盘,再到冗余电源和冗余风扇,所有关键组件都成对出现,确保任何单个部件的故障都不会导致整个系统宕机。
-
“共享架构”的物理实现: 这张图清晰地展示了上一页提到的“全共享架构”是如何实现的。两个独立的控制器“大脑”(CPU)被放置于同一个机箱内,通过共享的硬盘背板共同访问前端的24块双端口NVMe硬盘,这是整个共享存储设计的物理基础。
-
高性能的硬件规格: 除了高可用性,该产品还定位在高性能。采用支持高功耗CPU的平台、最新的DDR5内存和PCIe 5.0总线,配合全NVMe存储介质,旨在提供强大的IO处理能力,满足严苛的应用性能需求。
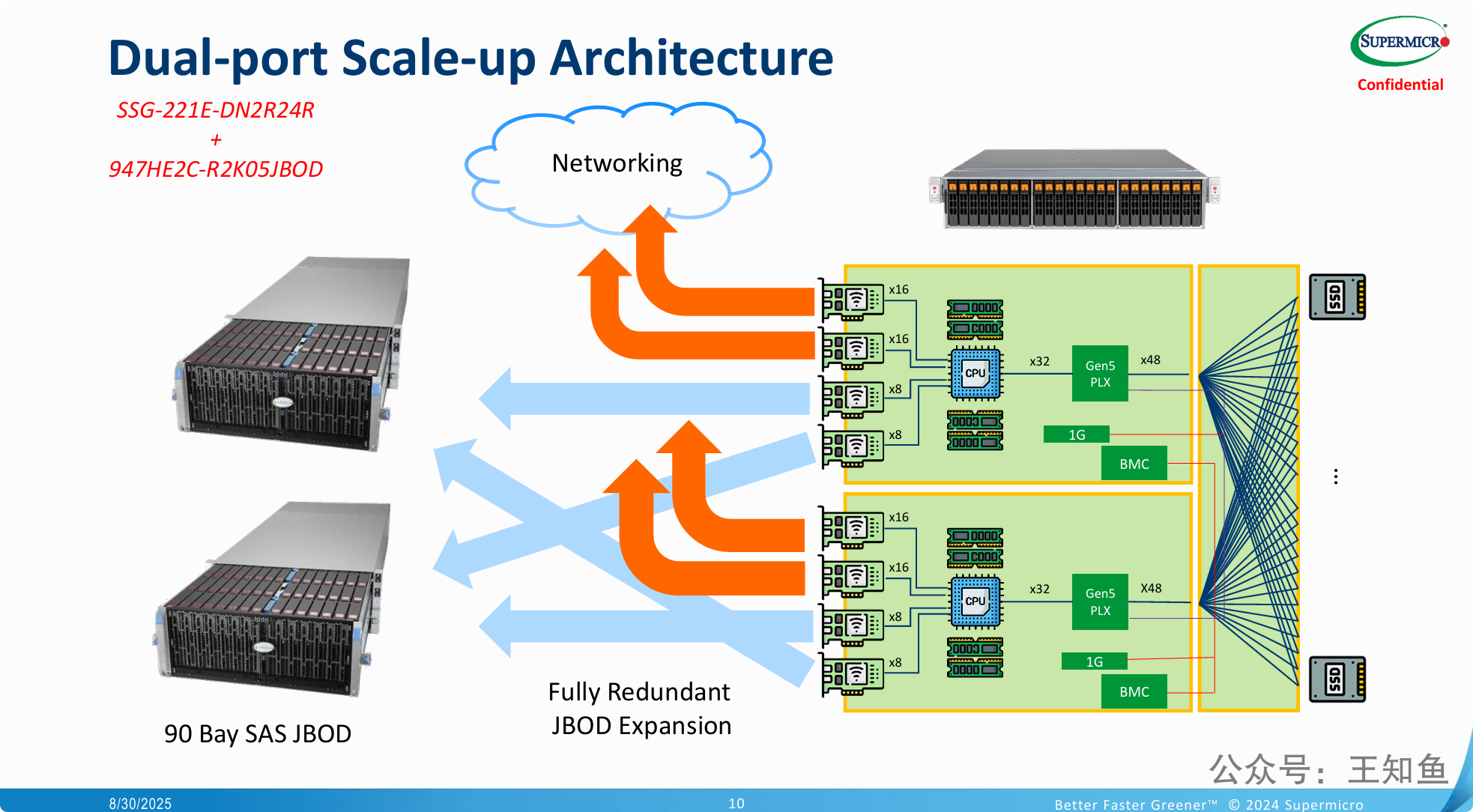
解释了 纵向扩展的核心逻辑:
-
双控制器内部结构: 绿色方框内清晰地展示了两个完全对称、相互独立的控制器。每个控制器内部都包含 CPU、内存、用于管理带外功能的 BMC 芯片,以及一个关键的 Gen5 PLX 芯片。PLX 是一种 PCIe 交换机,用于扩展CPU提供的PCIe通道,从而可以连接更多的设备。
-
前端客户网络(橙色箭头): 每个控制器通过其 PCIe 插槽(x16、x8)连接到外部网络(图中的云“Networking”)。这代表了数据中心或用户的应用服务器访问存储的路径。由于两个控制器都有独立的网络连接,因此前端访问路径是完全冗余的。
-
后端硬盘扩展(蓝色箭头): 这是本图的重点。两个控制器同样通过其 PCIe 插槽,分别引出独立的路径连接到左侧的 JBOD 扩展柜。这部分被明确标注为 “全冗余 JBOD 扩展 (Fully Redundant JBOD Expansion)”。这意味着每个控制器都有自己专属的、不共享的通道去访问扩展柜里的所有硬盘。
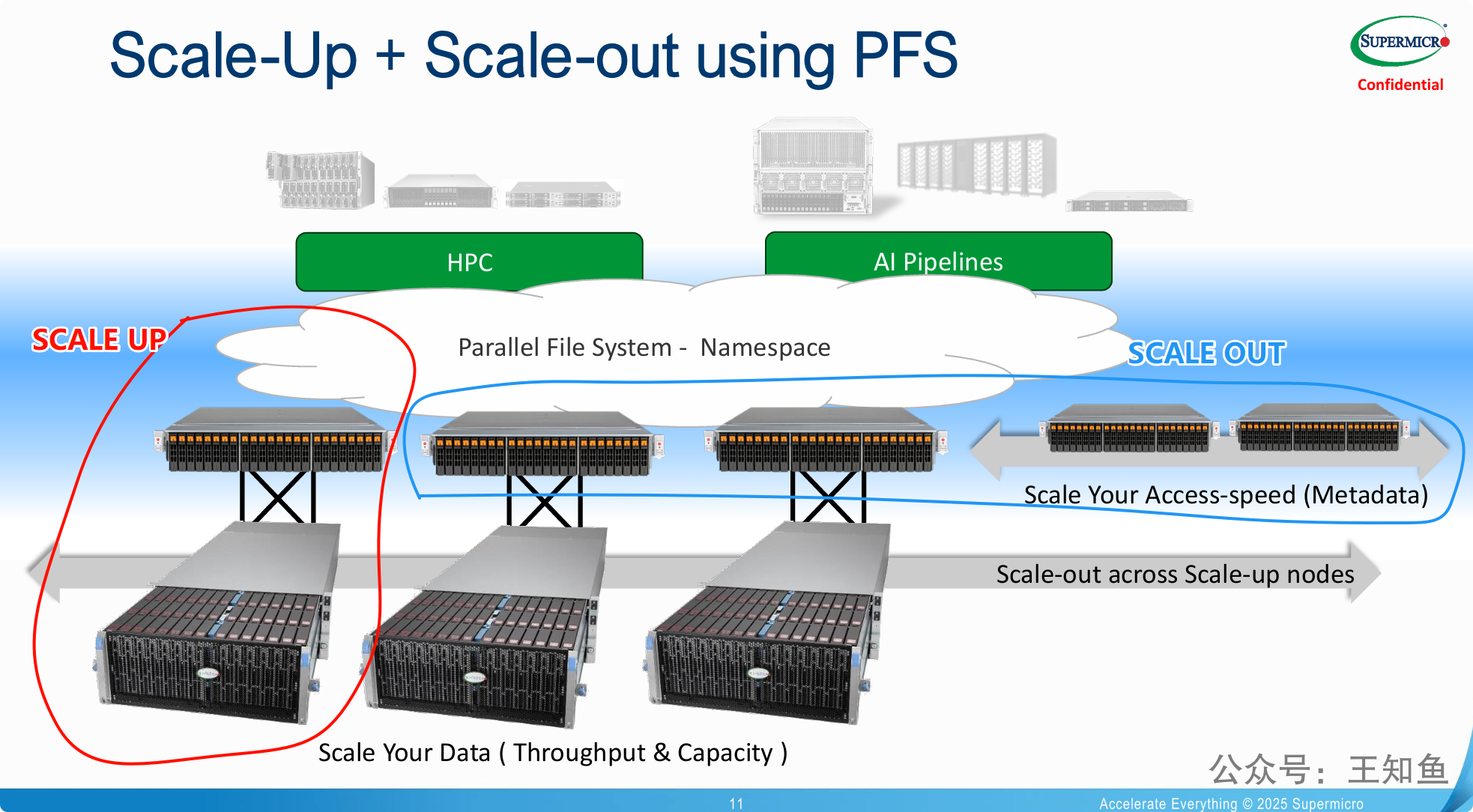
面向 HPC 和 AI/ML 的数据密集型场景,经典的 SCALE UP 架构往往因为 元数据节点的性能瓶颈而无法满足海量数据并发访问需求,因此需要寻求 SCALE OUT 架构。
这张图有一定歧义,通常大规模 PFS(并行文件存储) 架构,元数据和存储节点 是分开,通过高速网络连接,而不是像图中 元数据+存储节点 这样单独横向扩展出来。
-
混合扩展模式的优势: 它不再推崇单一的扩展模式,而是主张“两者兼得”。
-
纵向扩展 (Scale-Up) 用于构建单个大容量、高吞吐的数据存储节点,实现成本效益。
-
横向扩展 (Scale-out) 用于将多个这样的节点(包括元数据节点和数据节点)组成一个更大的集群,实现性能和容量的近乎无限增长。
-
-
软硬件解耦与分层设计: 该架构最精妙之处在于将元数据(Metadata)处理和数据(Data)存储分离。
-
用高速、低延迟的服务器(通常是全闪存)专门处理元数据,解决海量小文件访问和快速文件查找的瓶颈。
-
用高容量、高吞吐的服务器专门存储数据,解决大文件读写和总容量的需求。
-
这种分离设计可以针对不同的性能瓶颈进行独立、精准的扩展,避免资源浪费。
-
-
并行文件系统 (PFS) 是关键: 如果没有PFS这个软件层,上述所有硬件只是独立的服务器堆砌。PFS将它们“粘合”成一个有机的整体,对上层应用提供一个单一、易于访问的入口,并负责在底层高效地调度IO,实现并行读写,从而最大化发挥出整个硬件集群的潜力。

发布并展示Supermicro旗舰级的 “EDSFF Petascale” 全闪存服务器系列,强调其是面向未来的、性能和密度极致化的数据平台。
-
全面拥抱下一代标准 (EDSFF & CXL): 该产品线的基石是全面采用了EDSFF闪存规格。Supermicro认为EDSFF相比传统U.2在散热、功耗、密度和通用性上都有巨大优势。同时,前瞻性地集成了CXL技术,突破了传统内存容量的限制,直击AI和内存计算等前沿应用的痛点。(在存储节点配置CXL扩展插槽,这种设计合理吗?)
-
极致的性能与密度: 通过具体的性能数据(1.9PB容量、3000万IOPS、230GB/s带宽),该PPT旨在传递一个信息:这系列产品在存储的 “速度” 与 “容量” 两个关键维度上都达到了业界顶尖水平,是构建PB级(Petascale)高性能存储集群的理想“积木”。
-
前所未有的平台选择自由度: 一个巨大的亮点是它同时支持来自 Intel、NVIDIA (ARM架构 Grace) 和 AMD 的最新CPU平台。这给了客户极大的灵活性,可以根据自己的应用生态、软件栈和采购偏好来选择最合适的计算核心,而不是被锁定在单一技术路线

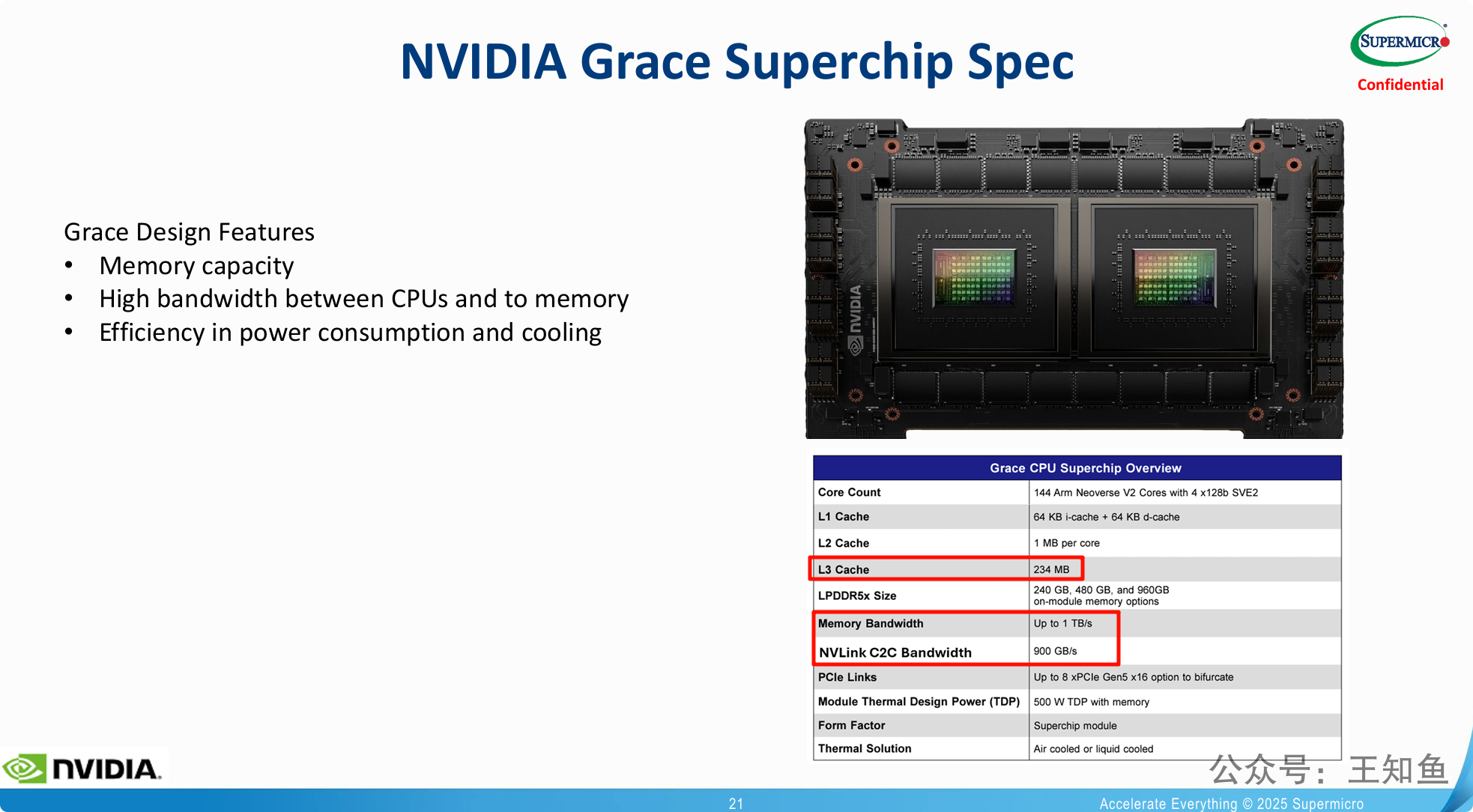

搭载NVIDIA Grace CPU的Supermicro Petascale服务器,是为NVIDIA AI生态系统量身打造的、性能和效率最优的存储解决方案。
-
原生生态集成是最大卖点: 最大的亮点在于与NVIDIA AI技术栈的“无缝”和“深度”集成。通过对GDS、DOCA、CUDA的原生支持,它能够最大化地发挥NVIDIA AI工厂中GPU和DPU的潜力,消除传统架构中的I/O瓶颈。
-
专为AI负载的性能瓶颈而设计: 该架构直接针对AI应用中最常见的两大瓶颈进行优化:
-
通过 1TB/s的超高内存带宽,解决了大型模型和数据集对内存带宽的极致需求。
-
通过 GDS认证 和优化的IO架构,解决了GPU集群的数据供给问题,让昂贵的GPU不必再“空等”数据。
-
-
极致的能效比: 对于需要部署成百上千个节点的大规模AI集群而言,功耗和运营成本(TCO)是至关重要的考量因素。该产品利用ARM架构的Grace CPU,主打 “高性能与低功耗” 的能效优势,直击大规模部署的痛点。
NVLink 的高带宽优势正逐渐衍生为存储产品的设计原则。
关于 DOCA
DOCA 是一个缩写,全称是 Data-Center-Infrastructure-on-a-Chip Architecture,中文可以理解为 “数据中心芯片级基础架构”。
简单来说,DOCA 是 NVIDIA 为其 BlueField DPU(数据处理器)打造的软件开发套件(SDK)和统一的软件平台。
我们可以用一个类比来快速理解它:
可以简单地将 DOCA 理解为 “DPU 领域的 CUDA”。
-
CUDA 是让开发者能够调用和编程 GPU 强大并行计算能力的软件平台。
-
而 DOCA 则是让开发者和数据中心管理员能够调用和编程 DPU 强大基础架构处理能力的软件平台。


一种新的存储系统设计范式:即用DPU完全取代传统的x86 CPU,来充当存储系统的“大脑”。
-
存储控制器的革命 (“DPU即控制器”): 最大的亮点是“Self-host DPU”概念的落地。这意味着存储的控制平面和数据平面都下沉到了DPU上,实现了存储与计算服务器的彻底解耦(Disaggregation)。一个装有BlueField DPU的JBOF,本身就构成了一个完整的、可通过网络访问的高性能存储节点。
-
极致的能效是关键驱动力: 该方案最直接、最吸引人的优势是显著降低功耗(15-20%)。在电费高昂、追求绿色节能的大规模数据中心里,这是一个极具竞争力的价值主张,能有效降低总体拥有成本(TCO)。
-
展示了具体落地的产品: Supermicro通过展示具体的服务器型号和可维护的硬件设计,表明这并非一个纯理论概念,而是已经产品化的、可以实际部署的解决方案。
值得一提的是:基于 DPU 的存储方案,VAST 的 D node 节点已经采取这种设计方案,在高性能场景有过落地实践。

展示了存储架构从 “以服务器为中心的传统DAS架构” 到 “以网络为中心的现代解耦架构” 的演进。
-
JBOD 代表过去/现在(服务器的附属品):
-
它是一种简单、直接的容量扩展方式,将存储视为特定服务器的“外挂硬盘盒”。
-
这种模式的主要缺点是形成了 “存储孤岛” ,资源无法灵活共享,扩展性受限于单个控制器的能力。
-
-
JBOF (+DPU) 代表未来(网络的原生公民):
-
它通过将智能(DPU)直接赋予存储端,将存储从服务器的附属品解放出来,使其成为一个独立的、可通过网络访问的、可共享的服务节点。
-
这种模式是构建软件定义存储和可组合式分解基础设施(CDI) 的基础。它打破了存储孤岛,允许计算和存储资源按需、独立地扩展和组合,是现代云数据中心的理想架构。
-