
Siemens EDA:MR-DIMM:AI内存性能倍增器
问题意识
GPU计算范式在最近两年逐渐取得共识,DRAM行业的主要视角都投向HBM,追求片上集成的高带宽方案,传统DDR 服务器内存方案,相比之下,门可罗雀,但这并不意味着DRAM设计停止不前。本文介绍的 MR- DIMM (多路复用Rank 双列直插内存模块)技术,可在现有服务器模块上实现内存访问速率的翻倍效率。
👉 划线高亮 观点批注
Main


AI领域中不断演进的内存需求,分为以下几个部分:
-
Bandwidth Needs (带宽需求):
-
AI/ML模型需要在内存和加速器(如GPU、TPU)之间移动海量数据。
-
标准的内存架构往往无法足够快地提供数据,导致处理器因等待数据抓取而空闲,从而造成“带宽瓶颈”。
-
-
Latency Issues (延迟问题):
-
首先定义了延迟(Latency),即从内存中获取数据所需的时间。
-
随后指出,在AI训练中,对大型数据的重复访问会导致漫长的抓取周期,从而拖慢了整体的计算速度。
-
-
Capacity Constraints (容量限制):
-
大型AI模型需要极高的内存容量,以避免持续的“分页”(paging)操作(即在高速内存DRAM和低速存储之间来回交换数据)。
-
当DRAM容量受限时,会导致数据频繁地移向更慢的存储设备,从而显著降低系统性能。
-
-
Poor Memory Access Patterns (不良的内存访问模式):
-
AI工作负载通常具有“不规则的内存访问”特性,而传统的内存层级结构(memory hierarchies)并未针对这种模式进行优化。
-
这种不匹配会导致“缓存未命中”(cache misses)、低效的数据预取(inefficient data prefetching)以及增加的内存访问开销(memory access overhead)。
-
-
Parallelism in Memory Access (内存访问的并行性):
-
AI加速器以大规模并行的方式处理运算,然而传统的内存子系统并非为大规模并行数据访问而设计,这就造成了一种“不匹配”(mismatch)。
-
这种不匹配限制了多线程的吞吐量,并会导致处理流水线(processing pipelines)发生停顿(stalls)。
-
-
Power and Thermal needs (功耗与散热需求):
-
对高内存带宽和大容量的需求会显著增加系统的功耗和产生的热量。
-
为了将温度控制在热设计限制之内,系统可能会对性能进行“降频”或“节流”(throttle),这在运行AI应用时尤其常见,因为AI应用负载极高。
-
-
Memory Scaling (内存扩展性):
-
随着模型规模的增长(达到数十亿参数级别),内存技术在速度和效率上的发展速度并没有与之成比例地扩展。
-
这个日益扩大的差距,限制了AI模型能够被训练或部署的速度和效率。
-

整张PPT围绕MR-DIMM技术,从定义、关键组件、主要特性、数据速率和容量五个方面进行了阐述:
-
MRDIMM (定义):
-
全称: Multiplexed Rank Dual In-line Memory Module,即“多路复用Rank双列直插内存模组”。
-
定位: 内存模组技术的下一代演进方向。
- 深入理解DRAM-3:DDR5 一文中介绍了当前常用的DDR5模组类型
-
目标应用: 专为AI(人工智能)和HPC(高性能计算)工作负载设计的高性能内存方案。
-
-
Key Components (关键组件):
-
MRCD (Multiplexing Registered Clock Driver): 多路复用寄存时钟驱动器。它的核心功能是管理时钟信号,以实现精密的时序控制。
-
MDB (Multiplexing Data Buffer): 多路复用数据缓冲器。它负责实现高速数据的复用(muxing)和解复用(demuxing),并且有助于降低CPU的负载。
-
-
Key Features (主要特性):
-
Rank支持: 每条DIMM(内存模组)最高支持4个Rank(内存区块)。
-
时序模式: 支持1N和2N两种时序模式。
-
操作模式: 具备两种操作模式,即Mux模式(多路复用模式)和Rank模式。
-
-
Data Rates (数据速率):
-
当前速率: 目前最高可支持到 12,800 MT/s(每秒兆次传输)的惊人速率。远超当前DDR5 速率
-
未来潜力: 技术上为未来更高的速率(如 17,600 MT/s)做好了准备,具备良好的可扩展性。
-
-
Capacity (容量):
- 单条容量: 单条DIMM模组的容量最高可达 256 GB。
为什时序控制成为GPU计算场景的内存优化方向?
在协同GPU的场景中,精密的内存时序控制之所以格外重要,根本原因在于GPU“大规模并行”和“同步执行”的工作特性。 这两个特性将内存时序的任何微小瑕疵都进行了指数级的放大,最终导致整个计算集群的效率雪崩。
我们可以从以下三个层面来理解:
1. 匹配GPU的“齐步走”特性,防止“一人迟到,全军等待”
GPU的工作模式:GPU拥有数千个计算核心,它通常会将这些核心分成小组(例如NVIDIA的Warp或AMD的Wavefront)。在执行任务时,一个小组里的几十个核心往往会“同步执行”同一条指令,只是处理的数据不同。
时序控制的影响:当这些核心需要从内存中读取数据时,它们也期望能够“同时”拿到各自的数据,然后一起进入下一步计算。如果内存时序控制不精密,导致某个核心的数据因为信号抖动或时序偏差而晚了哪怕一两个时钟周期,那么为了保持同步,整个小组的所有其他核心都必须停下来等待这个最慢的成员。
重要性体现:在一个只有8核的CPU上,一个核心等待可能只会影响1/8的性能。但在一个有10000个核心的GPU上,一次微小的时序错误可能导致几百甚至上千个核心陷入“流水线停顿”(Pipeline Stall)。这种停顿的累积效应是灾难性的,会极大地浪费GPU宝贵的算力。因此,MRCD提供的精确定时,就是确保这支庞大的“计算军队”能够令行禁止、齐步前进的关键。
2. 保障超高数据速率下的“信号完整性”,让高速成为可能
物理极限:GPU协同工作需要极高的内存带宽(例如MR-DIMM的12,800 MT/s)。在如此高的频率下,时钟信号在PCB板上传输时,会变得非常脆弱,容易受到电磁干扰、信号衰减和串扰的影响,导致信号“抖动”或“失真”。
时序控制的角色:MRCD就像一个“信号中继站和整形器”。它位于内存控制器和内存颗粒之间,接收来自控制器的时钟信号,然后对其进行“净化、放大和重新驱动”,再以最纯净、最精准的形态发送给各个内存颗粒。
重要性体现:没有MRCD这样的组件进行精密的时序和信号管理,内存根本无法稳定运行在那么高的频率上,或者会出现大量的读写错误。它不是让内存“跑得更快”,而是让内存“能够在那么快的速度下稳定跑起来”,这是协同GPU发挥其全部带宽优势的物理基础。
3. 最大化“有效带宽”,填饱GPU这个“吞数据巨兽”
理论带宽 vs. 有效带宽:内存的标称速率是“理论带宽”,但在实际工作中,因为时序等待、数据校验、错误重传等开销,GPU实际能用到的“有效带宽”会打折扣。
时序控制与效率:精密的时序控制可以显著减少不必要的等待周期和数据出错的概率。每一次成功的、无需重试的读写,都在逼近理论带宽的上限。
重要性体现:GPU对数据的渴求是海量的,就像一个永远填不饱的巨兽。有效带宽每提升1%,GPU的整体性能可能就会有相应的提升。MRCD通过提供精准的时序控制,本质上是在减少“数据通路”上的摩擦和损耗,让数据流更顺畅、更高效地灌入GPU中,从而最大化有效带宽。
总结来说, 对于CPU,内存时序很重要;但对于GPU,它是决定生死的命脉。因为GPU的并行架构放大了时序问题的影响,其高带宽需求又对时序控制的物理实现提出了极限挑战。像MRCD这样的技术,正是为了解决这一核心矛盾而诞生的,它确保了在超高速度下,内存系统依然能够与GPU的成千上万个核心“精准同步”,从而释放出AI和HPC应用所需的澎湃算力。
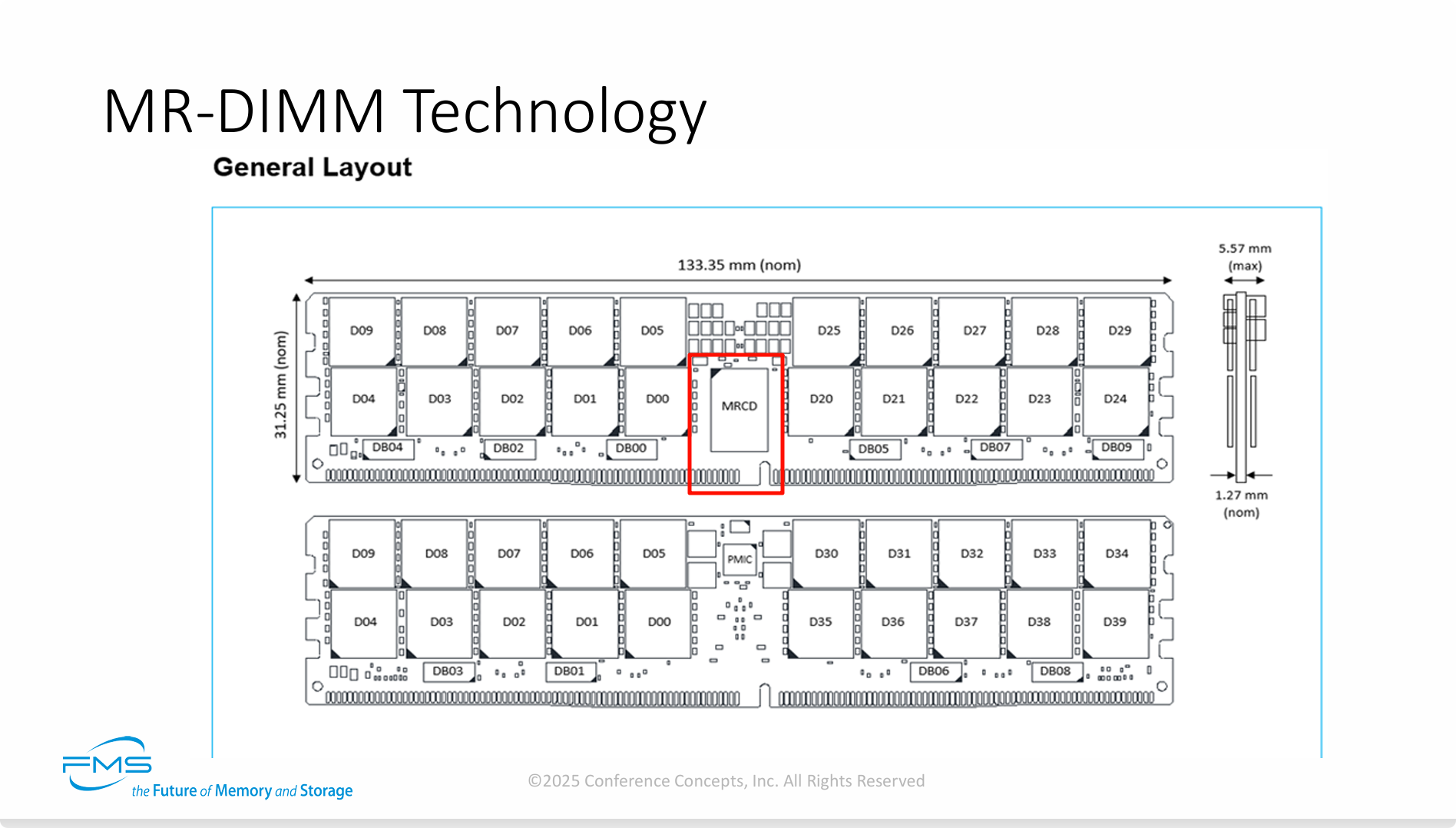
这张PPT的核心信息是通过展示MR-DIMM的实体布局,证明了这项新技术在工程上的可行性和对现有生态的兼容性。 它将前一页PPT中的抽象技术概念具象化为具体的硬件设计。
关键信息提炼如下:
-
架构的物理实现: 该布局图清晰地展示了MR-DIMM的核心架构:一个中央MRCD负责指挥和控制,多个分布式MDB负责处理高速数据流。这种设计是为实现超高数据速率下的信号完整性而优化的。
-
保持标准外形(Form Factor): 尽管内部采用了革命性的技术,MR-DIMM在物理尺寸上严格遵守行业标准。这意味着服务器制造商可以平滑地升级采用这项技术,而无需重新设计主板或机箱,大大降低了应用门槛。
-
现代服务器内存的设计典范: 板载PMIC的集成,表明MR-DIMM是一个完整的高级内存解决方案。在本地管理电源可以提供更佳的电能质量和效率,这对于驱动高速、高密度的DRAM颗粒至关重要,是其高性能和稳定性的有力保障。

这张PPT的核心观点是,MR-DIMM的Mux模式是一种通过“时分复用”的巧妙设计,在不提高DRAM颗粒自身频率的前提下,实现主机内存带宽翻倍的革命性技术。
关键信息提炼如下:
-
核心机制是“拆分”与“交替”: Mux模式将一个物理上的内存子通道,虚拟拆分成两个伪通道。然后利用MRCD这个“智能交通指挥”,在奇数和偶数时钟周期里,交替地访问这两个伪通道。
-
效率极高: 这种方式极具效率,因为它绕开了单纯提升DRAM颗粒频率所面临的功耗、散热和信号完整性等物理瓶颈。它榨干了数据总线在每个时钟周期的利用率。
-
类比理解: 这就像把一条单车道公路的通行效率提升一倍。我们不是拓宽公路(提高DRAM频率),而是在路的入口设置一个智能红绿灯,规定第1秒钟所有车开往A方向,第2秒钟所有车开往B方向。虽然路没变宽,但单位时间内的总车流量翻倍了。
工作原理图 (右上角图2):
-
该图展示了核心组件MRCD在Mux模式下的信号路径。
-
MRCD从内存控制器接收命令/地址信号(DCA总线),然后智能地将这些信号“多路复用”或分发到两个独立的伪通道(Pseudo-channel 0/PS0 和 Pseudo-channel 1/PS1)上。
-
图中的
_A和_B后缀,以及PS0和PS1的标签,清晰地表示了信号被路由到了两个不同的目标路径。

这张PPT的核心信息是,Rank模式是MR-DIMM技术提供的另一种工作选项,它牺牲了Mux模式的极限带宽,以换取类似标准LRDIMM的稳定运行模式、更强的兼容性以及对大容量配置的支持。
关键信息提炼如下:
-
模式定位:兼容与容量优先。Rank模式的设计目标不是追求极致性能,而是确保MR-DIMM能够像标准的DDR5 LRDIMM一样工作,这对于需要巨大内存容量的传统服务器应用或保证系统兼容性至关重要。
-
MRCD角色转变:在此模式下,MRCD的核心功能从一个高速“多路复用器”转变为一个“信号缓冲驱动器”。它的主要任务是降低内存控制器上的电气负载,并确保信号的完整性,从而允许在单个内存条上集成更多的Rank(即更大的容量)。
-
双模灵活性:综合前几张PPT,MR-DIMM被展现为一种灵活的“双模”内存技术。用户可以根据应用需求进行选择:
-
AI/HPC等带宽敏感型应用:使用Mux Mode,获得双倍带宽。
-
需要超大内存容量或兼容性的服务器应用:使用Rank Mode,获得稳定的大容量支持。
-
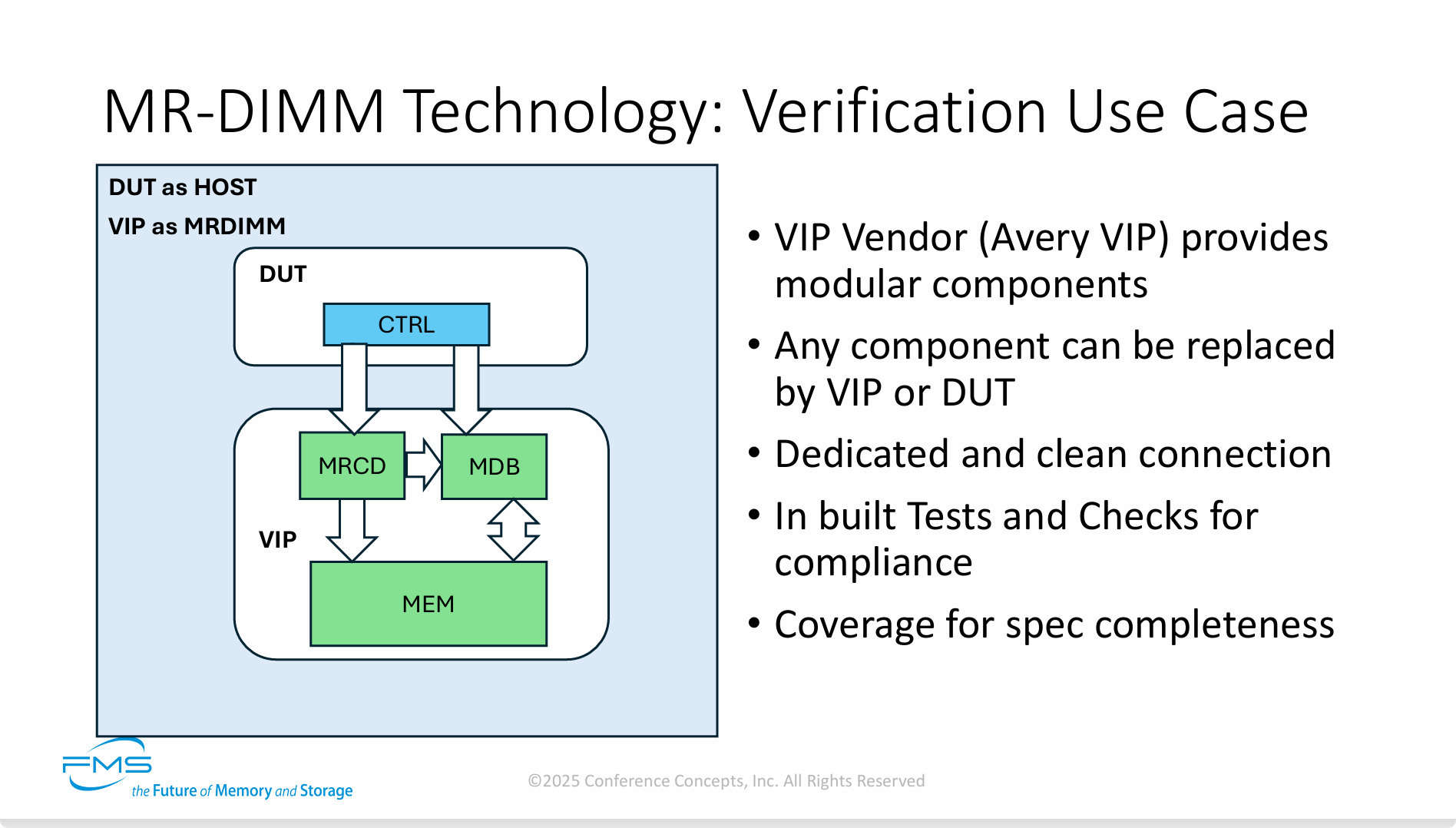
这张PPT的核心信息是,为了确保新的CPU或SoC芯片能够正确、可靠地支持MR-DIMM这一复杂的新技术,必须采用基于Verification IP (VIP) 的先进验证方法进行严格的仿真测试。
关键信息提炼如下:
-
验证的重要性: 对于像MR-DIMM这样的新标准,严格的先期验证是确保不同厂商(如CPU厂商和内存厂商)产品之间能够互联互通、协同工作的基石。
-
VIP的核心作用: Verification IP是现代芯片设计的关键工具。它相当于一个“虚拟陪练”或“官方认证的模拟器”,可以在没有真实物理硬件的情况下,让设计工程师对他们的芯片设计进行全面“体检”,从而在设计早期发现并修复潜在的bug。
-
流程价值: 这种在“数字世界”里进行的仿真验证,可以大大缩短产品开发周期,降低流片失败的风险,从而节省数百万美元的成本。它保证了当物理芯片被制造出来时,能够“即插即用”,正常工作。


第一部分:性能与规格 (来自第一张图片)
-
更高的内存带宽 (Higher Memory Bandwidth):
-
核心原理: 通过信号多路复用技术,在不增加物理接口宽度的情况下,将每个内存通道可访问的Rank数量翻倍,从而实现通道带宽的大幅提升。
-
性能数据: 带来了高达约 39% 的有效内存带宽提升。
-
具体对比: 将带宽从DDR5 RDIMM的约6,400 MT/s提升至约12,800 MT/s,能更快地为AI核心提供数据。
-
-
更优的延迟优化 (Better Latency Optimization):
-
性能数据: 在真实世界工作负载中,延迟降低了约40%。与128GB、6400 MT/s的RDIMM相比,其往返延迟更低。
-
技术解读: 这里提出一个关键的权衡点——虽然多路复用技术本身会轻微增加Rank间的访问延迟,但其带来的并行度提升和内部缓冲优化,对于AI这类工作负载而言,反而显著降低了“有效内存访问延迟”。
-
-
容量与规格 (Capacity & Form Factor):
-
容量支持: 单条模组支持32GB到256GB的容量,包括为2U/4U服务器设计的高版型(Tall Form Factor, TFF)。
-
能效优势: 使用32Gb的DRAM颗粒,可以制造出256GB的TFF MR-DIMM,而其功耗与使用16Gb颗粒的128GB模组相当。这意味着容量翻倍,功耗几乎不增加。
-
===
第二部分:效率与生态 (来自第二张图片)
-
散热与能效 (Thermal & Energy Efficiency):
-
散热表现: TFF高版型设计在相同的气流和功耗下,可将DRAM温度降低约20°C,这对于高密度服务器至关重要。
-
能源效率: 模组上集成的PMIC(电源管理芯片)缓冲器可以降低单次任务的功耗,从而提升数据中心关键的“每瓦性能”(performance-per-watt)指标。
-
-
生态系统兼容性 (Ecosystem Compatibility):
-
无缝升级: MR-DIMM可直接用于现有的DDR5 RDIMM插槽,并与英特尔Xeon-6/Granite Rapids CPU等新一代平台兼容,无需更换主板或修改BIOS。这是一个巨大的应用优势。
-
企业级特性: 完全保留了标准RDIMM的RAS特性(可靠性、可用性、可服务性),如ECC(错误校验码)、缓冲和纠错功能。
-
-
对AI负载的影响 (AI-Workload Impact):
-
实际效果: 在Xeon-6平台上进行的真实世界测试显示,MR-DIMM能够让AI类任务的完成速度提升约33%。
-
理想场景: 非常适合大语言模型(LLMs)、AI重训练和推理等需要CPU和加速器协同工作的工作负载。
-

内容分为四个层面,清晰地勾勒出了MR-DIMM的生态版图:
-
Standardization through JEDEC (JEDEC标准化):
-
标准发布: 权威的半导体标准组织JEDEC已于2024年初发布了MR-DIMM的官方标准。这意味着该技术已具备行业通用规范超过一年半。
-
标准内容: 该标准正式定义了DDR5 MR-DIMM,并规定其引脚和物理外形与DDR5 RDIMM保持一致(确保了物理兼容性),同时还定义了模组上的关键新组件,如PMIC(电源管理芯片)和MDB(数据缓冲器)。
-
-
Memory Vendor Adoption (内存厂商的采纳):
-
美光 (Micron): 已于2025年第一季度(大约半年前)推出了速率高达8800 MT/s的MR-DIMM样品,供下游厂商进行开发测试。
-
三星 (Samsung): 已成功开发出128GB容量、8000 MT/s速率的MR-DIMM模组,明确瞄准AI训练市场。
-
SK海力士 (SK hynix): 也已宣布了其MR-DIMM产品路线图,主要目标是HPC(高性能计算)集群中的AI推理应用。
-
(这表明全球三大内存颗粒厂商均已入局,上游供应链已经成熟。)
-
-
VIP Vendors Support (VIP供应商的支持):
-
作用: VIP(验证IP)工具的支持,使得SoC(系统级芯片)和内存控制器的开发者可以在大规模应用前,提前开始进行设计的验证工作。
-
价值: 这极大地加速了采用MR-DIMM技术的新服务器平台的上市时间 (time-to-market)。
-
现状: 关键的VIP供应商,如Avery,已经将MR-DIMM添加到了其产品组合中,表明设计工具链已经完备。
-
-
Server OEMs & Systems (服务器OEM和系统):
-
头部玩家: HPE(慧与)、Dell(戴尔)、Lenovo(联想)等全球顶级的服务器OEM厂商,均已在开发支持MR-DIMM的原型系统(Prototype systems)。
-
目标应用: 这些原型系统主要针对以下高端工作负载:
-
生成式AI工作负载 (Generative AI workloads)
-
大规模训练集群 (Large-scale training clusters)
-
内存分析 (In-memory analytics),例如 SAP HANA 和 Spark。
-
-
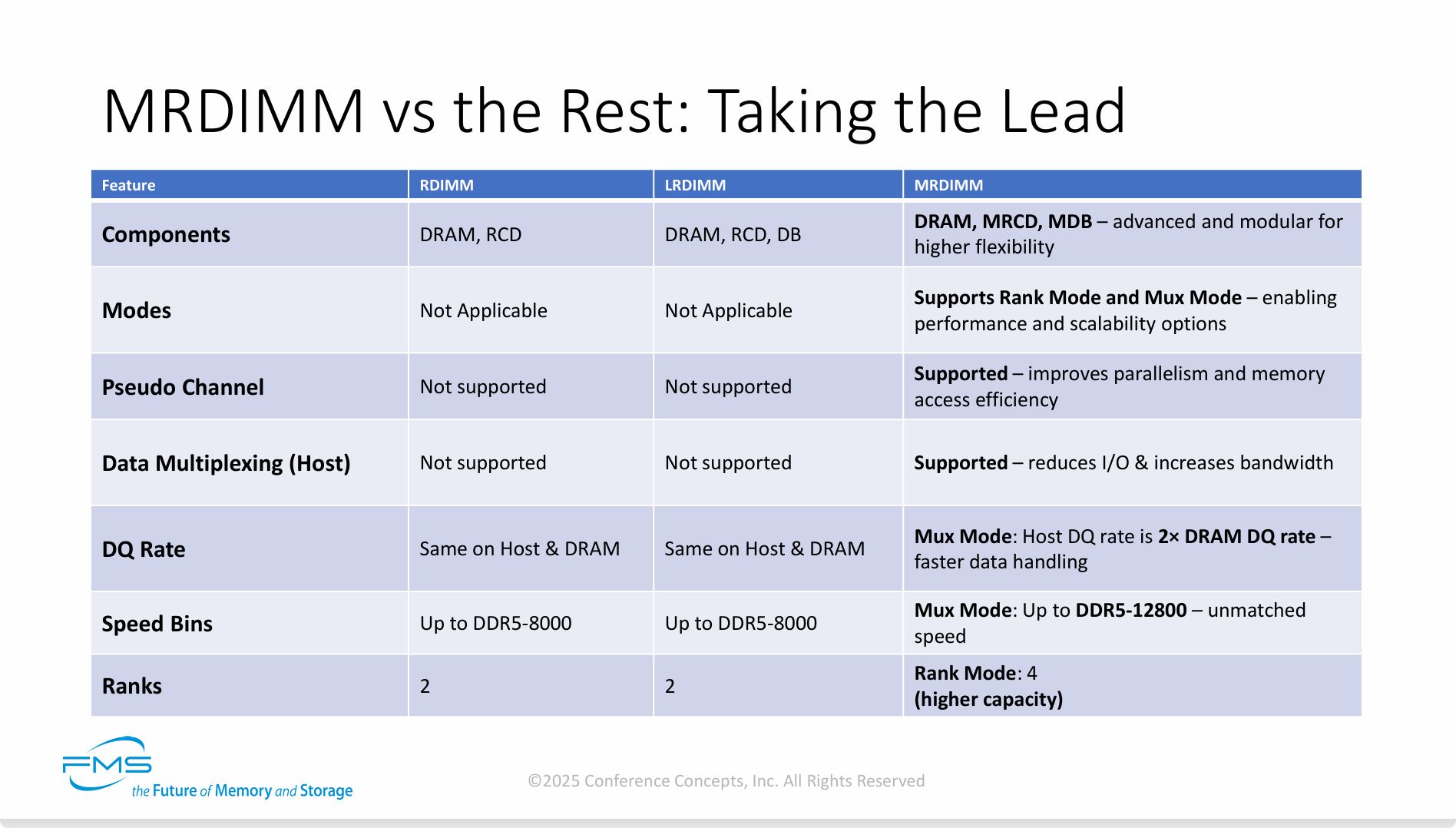
总结为以下四点:
-
架构上的根本性革新: MR-DIMM的领先并非简单的速度提升,而是源于其创新的架构。通过引入MRCD和MDB组件,实现了伪通道和数据多路复用等独有技术,从根本上改变了内存的工作方式。
-
无与伦比的性能: 其核心优势在于Mux模式。在该模式下,MR-DIMM能以两倍于DRAM颗粒的速率与主机通信,将内存速度推向了DDR5-12800的新高度,这是传统内存技术无法企及的。
-
前所未有的灵活性: “双模”设计是其另一大亮点。它既有追求极致性能的Mux模式,也有专注大容量和兼容性的Rank模式,能够灵活适应从AI/HPC到传统企业级应用等多样化的工作负载。
-
更高的集成密度: 即便在注重容量的Rank模式下,它也能支持比传统DIMM多一倍的Rank数量(4 vs 2),为构建超大内存容量的服务器提供了可能。
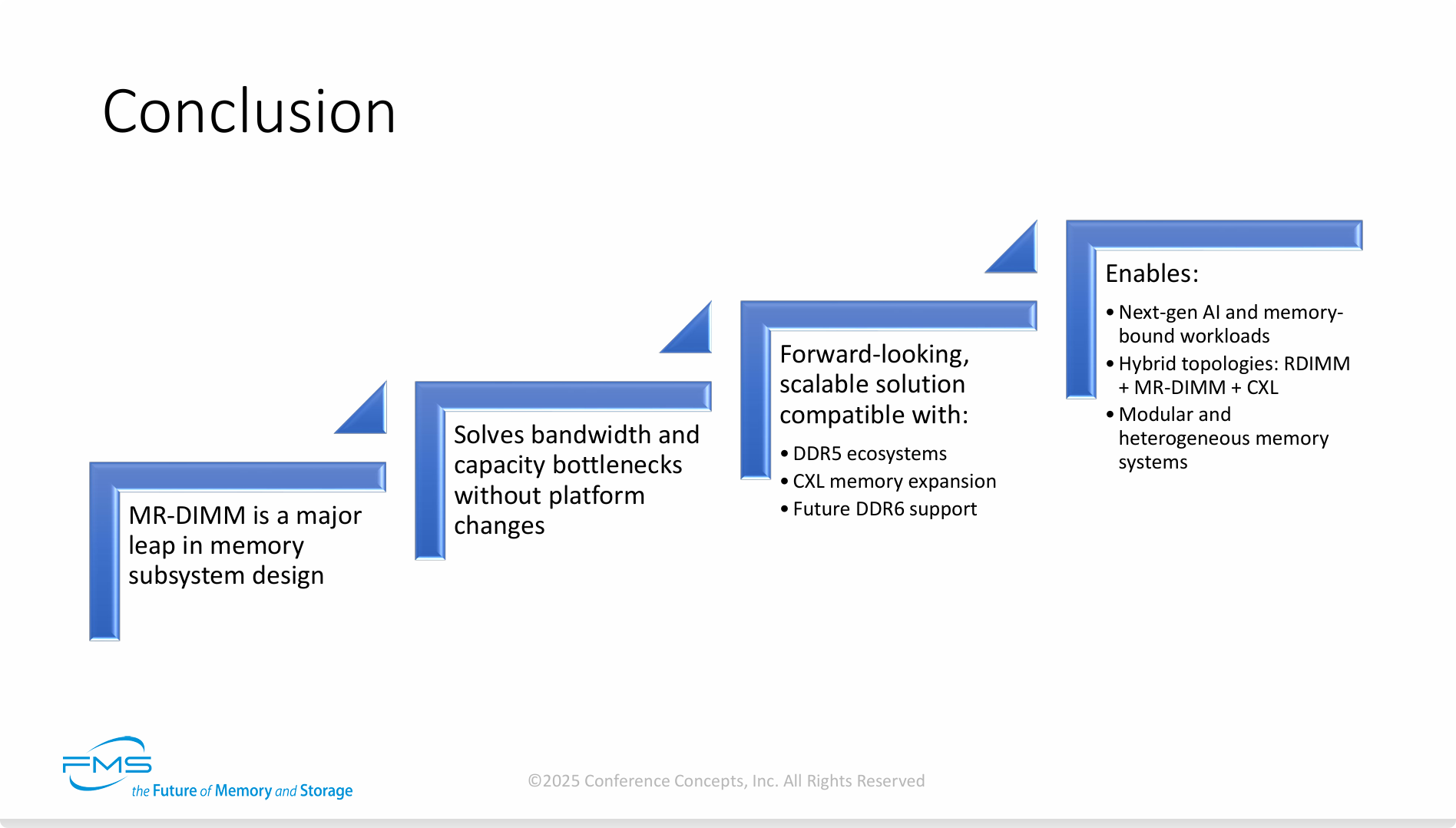
结论分为四个递进的层次:
-
第一步:技术定性 (Major Leap)
- 幻灯片的起点明确指出:“MR-DIMM是内存子系统设计的一次重大飞跃”。这强调了它的革命性地位,并非简单的产品迭代,而是一次根本性的技术突破。
-
第二步:核心价值 (Solves Bottlenecks)
- 紧接着,它重申了MR-DIMM最直接的价值主张:“在无需改变平台(platform changes)的情况下,解决了带宽和容量瓶颈”。这一点再次凸显了其“即插即用”的兼容性和高性价比的部署优势。
-
第三步:前瞻性与可扩展性 (Forward-looking)
-
这一步将MR-DIMM定位为一个着眼未来、可平滑扩展的解决方案。它清晰地指出,MR-DIMM兼容:
-
当前的DDR5生态系统:确保了当下的适用性。
-
新兴的CXL内存扩展技术:表明它可以融入下一代服务器的解耦式、池化内存架构中。
-
未来的DDR6标准支持:这是一个强有力的承诺,意味着MR-DIMM背后的核心架构思想具有长远的生命力,今天的投资在未来依然保值。
-
-
-
第四步:赋能未来 (Enables)
-
作为结论的顶层,这一步阐述了MR-DIMM技术最终将催生出怎样的新机遇和新架构。它能够赋能:
-
下一代AI和内存密集型工作负载。
-
混合内存拓扑结构:例如,在同一系统中混合使用传统的RDIMM、高性能的MR-DIMM以及通过CXL扩展的内存,构建分层、高效的内存系统。
-
模块化和异构化的内存系统:这是对混合拓扑的进一步抽象,代表了未来服务器内存设计的终极形态——灵活、按需组合、高度定制化。
-
-
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- MR-DIMM通过“时分复用”实现带宽翻倍,这与HBM等其他高带宽内存技术在解决AI内存瓶颈上的思路有何异同?各自的工程实现难度和成本效益如何?
- MR-DIMM与CXL内存扩展技术相结合,将如何重塑未来服务器的内存拓扑结构?你认为这种混合内存架构会带来哪些新的挑战和机遇?
- 在实际AI训练或推理场景中,你将如何根据模型规模、数据访问模式和预算,选择MR-DIMM的Mux模式或Rank模式?
原文标题:Revolutionizing Memory for AI/ML’s Future: MRDIMM
Notice:Human's prompt, Datasets by Gemini-2.5-Pro