
Bill Gervasi :存储架构的能效革命
问题意识
Efficiency in an AI/Crypto World
背景介绍(298字)
在追求极致性能的计算世界里,我们是否忽视了效率的本质?当CPU为了读取1比特数据而不得不加载64字节缓存行,当DRAM内部为服务小数据请求而空转99.7%的能量,当存储系统因4KB块大小与100字节实际需求的巨大鸿沟而浪费97.5%的I/O资源——这些触目惊心的数字揭示了现代计算架构深层次的效率危机。
本文通过系统性的技术分析,从CPU缓存行、DRAM物理机制到存储I/O的全链路视角,揭示了粒度失配这一根本性问题。随着AI和大数据时代的到来,传统"以计算为中心"的架构正面临前所未有的能效挑战。但危机中也孕育着变革:持久内存消除了检查点开销,CXL技术实现了细粒度数据访问,计算存储将计算推向数据源头——这些创新技术正在重塑我们对效率的认知。
作为技术从业者,我们是否应该重新审视"性能至上"的思维定式?当每一瓦特电力都承载着环境责任,当数据量呈指数级增长,效率优化已不再是可选项,而是生存的必然选择。
读者收获
- 深度理解现代计算架构的效率瓶颈:掌握从CPU缓存到存储系统的全链路效率问题根源
- 掌握新兴能效技术原理:了解持久内存、CXL协议和计算存储等前沿技术的核心机制
- 获得架构设计新视角:学会从"数据驱动"而非"计算中心"的角度思考系统优化
- 具备能效评估能力:能够量化分析不同技术方案在真实场景下的能效表现
开放性问题
-
在您的工作场景中,是否遇到过类似的粒度失配问题?您是如何通过架构优化或技术选型来应对的?
-
随着CXL和持久内存技术的成熟,您认为未来3-5年内企业级计算架构会发生哪些根本性变革?这些变革对应用开发模式会产生什么影响?
-
计算存储虽然能显著降低数据移动开销,但面临着标准化和编程复杂性的挑战。在您看来,什么样的应用场景最适合率先采用计算存储方案?业界需要建立哪些基础设施来降低其使用门槛?
👉 划线高亮 观点批注
Main
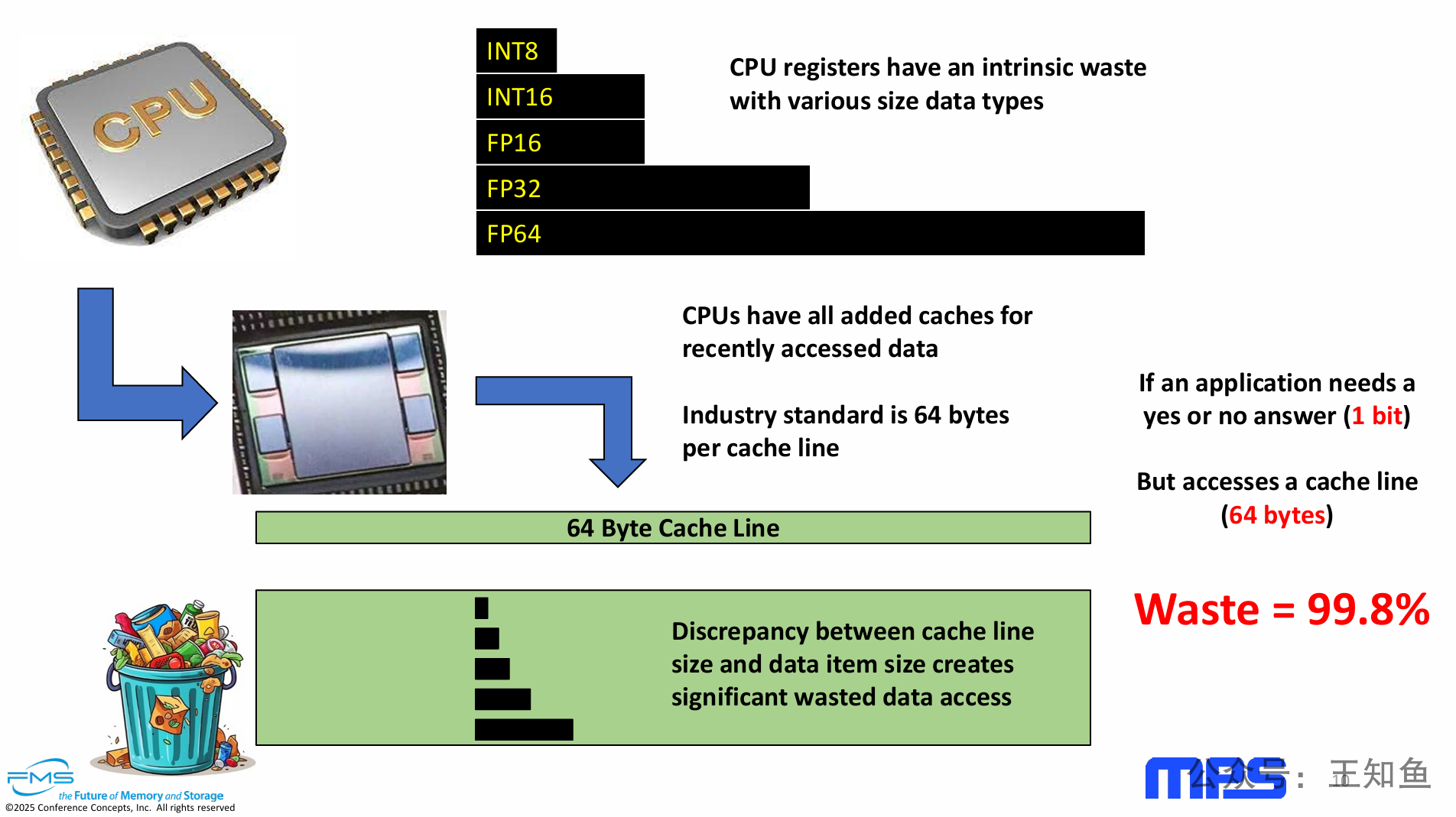
PPT的核心观点是,现代CPU的缓存架构存在严重的效率问题,其根源在于应用程序实际需要的数据大小与CPU缓存行固定大小(64字节)之间的巨大差异。
关键信息如下:
-
根本矛盾:CPU以固定的、较大的数据块(64字节缓存行)为单位进行数据读取,而应用程序通常只需要其中很小的一部分数据。
-
资源浪费:这种不匹配导致了显著的“数据访问浪费”,即大量被传输和存储在缓存中的数据实际上是无用的。这不仅浪费了内存带宽,也占用了宝贵的缓存空间,并可能增加不必要的功耗。
-
问题普遍性:这个问题是CPU架构固有的,影响所有需要处理小粒度数据的应用场景。PPT通过一个1比特数据的极端例子,清晰地量化了这种浪费可能达到的惊人程度(99.8%)。
提升 CPU 缓存行效率,最现实、成功的工程实践就是当下GPU和多核处理器的范式革新,通过更多线程的并发读取,提高计算效率的同时,完整消化掉单个缓存行的数据。
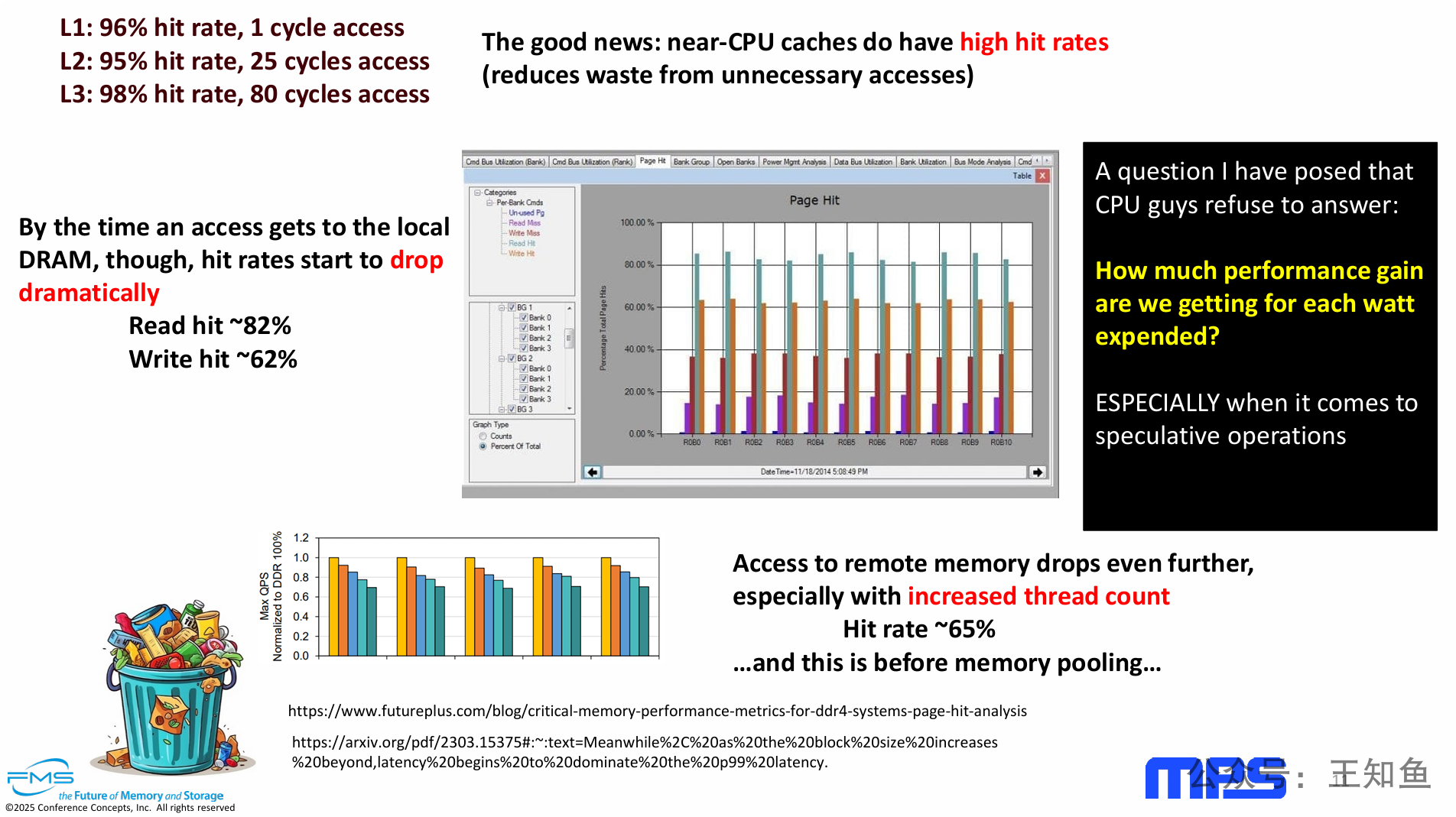
PPT的核心观点是:尽管CPU内部的多级缓存非常高效,但数据访问的瓶颈已经转移到了CPU与主内存(DRAM)以及远程内存的交互上,并且随着核心数/线程数的增加,这个问题愈发严重,最终引出了对当前CPU设计中“性能与功耗效率”权衡的深刻质疑。
-
瓶颈转移:性能瓶颈已不在CPU缓存本身,而在缓存未命中后对DRAM的访问。从高达95%以上的缓存命中率,骤降至82%甚至65%的DRAM命中率,形成了一个性能“断崖”。
-
扩展性问题:在多线程和远程内存访问(如多路服务器、内存池化)的现代计算场景下,内存访问的命中率和性能会进一步恶化,显示出当前架构的扩展性瓶颈。
-
终极拷问:演讲者认为业界过于追求绝对性能,而忽略了能效(性能/功耗比)。特别是像推测执行这类“以浪费换性能”的技术,其真实的能效价值需要被重新审视和量化。
总而言之,这张PPT通过数据层层递进,指出内存访问是当前计算架构的“阿喀琉斯之踵”,并升华主题,呼吁行业从关注“速度”转向关注“效率”,即每一瓦特电力所带来的真实性能回报。
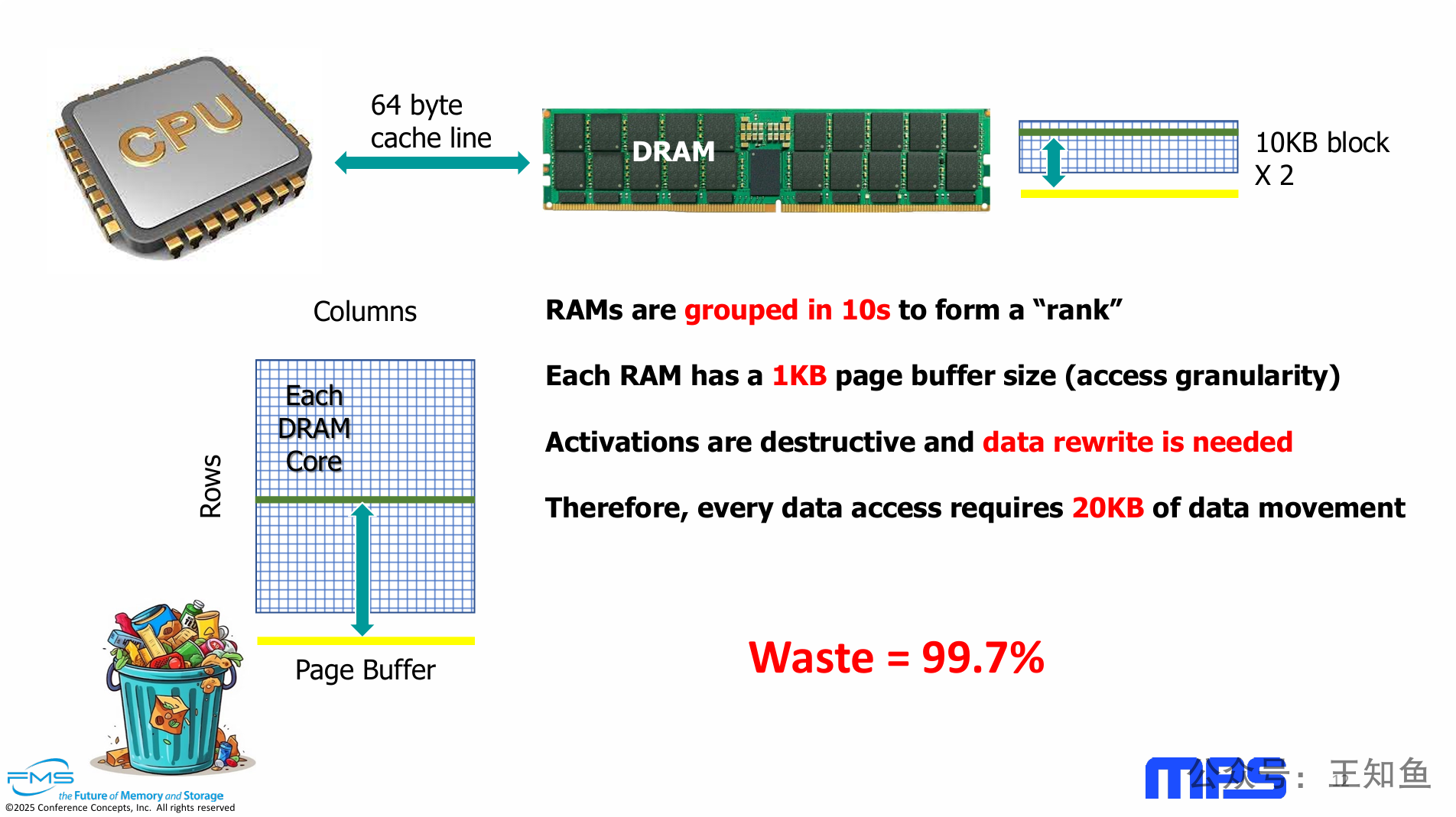
PPT的核心观点是,现代DRAM的底层物理和架构设计,导致了CPU的小数据请求被极度放大,在DRAM内部产生了巨大的、不必要的数据移动,造成了高达99.7%的惊人浪费。
-
粒度失配(Granularity Mismatch):问题的根源在于CPU请求的数据粒度(64字节)与DRAM的物理访问粒度(本例中为1KB/芯片)之间存在巨大差异。
-
架构放大效应:DRAM通过并行使用多个芯片(组成Rank)来提升带宽的设计,进一步将内部数据移动量放大了数倍(本例中为10倍)。
-
物理原理开销:DRAM“破坏性读取”的物理特性,强制要求每次读取后都必须进行一次等量的数据写回,使得总数据移动量直接翻倍。
幻灯片揭示了在内存子系统中一个比CPU缓存行更深层次、更严重的效率问题。它表明,为了获取极少量的数据,整个内存系统在内部“空转”了大量的能量和带宽,这为提出颠覆性的内存技术或架构创新提供了强有力的论据
===
DRAM内部工作原理(左下图和右侧文字):
-
DRAM核心结构:左下角的图表展示了单个DRAM芯片核心的结构,它是一个由“行”(Rows)和“列”(Columns)组成的二维矩阵。底部有一个“页缓冲区”(Page Buffer),也叫行缓冲区(Row Buffer)。
-
访问基本单位:当需要读取数据时,DRAM并不能精确地只读取64字节。它的基本操作是“激活”(Activate)一整行,并将这一整行的数据全部读入到页缓冲区中。这个页缓冲区的大小,就是DRAM的“访问粒度”(access granularity)。
-
具体参数(右侧文字):
-
Each RAM has a 1KB page buffer size:在本例中,单个DRAM芯片的页缓冲区大小为1KB。这意味着哪怕只访问1个比特,也必须先将整整1KB的数据从存储阵列移动到缓冲区。 -
RAMs are grouped in 10s to form a "rank":在内存系统中,多个DRAM芯片会并行工作以提供更高的数据带宽。这个组合被称为一个“Rank”。在此示例中,一个Rank由10个DRAM芯片组成。因此,一次内存访问会同时激活这10个芯片的对应行,总共移动1KB/芯片 * 10个芯片 = 10KB的数据到各自的页缓冲区。 -
Activations are destructive and data rewrite is needed:这是DRAM的一个关键物理特性。读取操作是“破坏性的”,因为读取时会将存储单元(电容)的电荷耗尽。因此,为了不丢失数据,在读取之后,必须立即将页缓冲区中的10KB数据重新写回(Rewrite)到原来的那一行中去。
-
需要指出的是:此处 CPU单次读取/缓存行 来定义缓存冗余、利用率低的方法是偏颇的,因为CPU的时钟速率比DRAM速率高出数量级,因此通过多缓存数据来提高CPU下次数据命中是SRAM/DRAM的经典设计,一次读取,多次命中是DRAM的原型,不能忽视多读取的数据对下一次计算命中的价值。
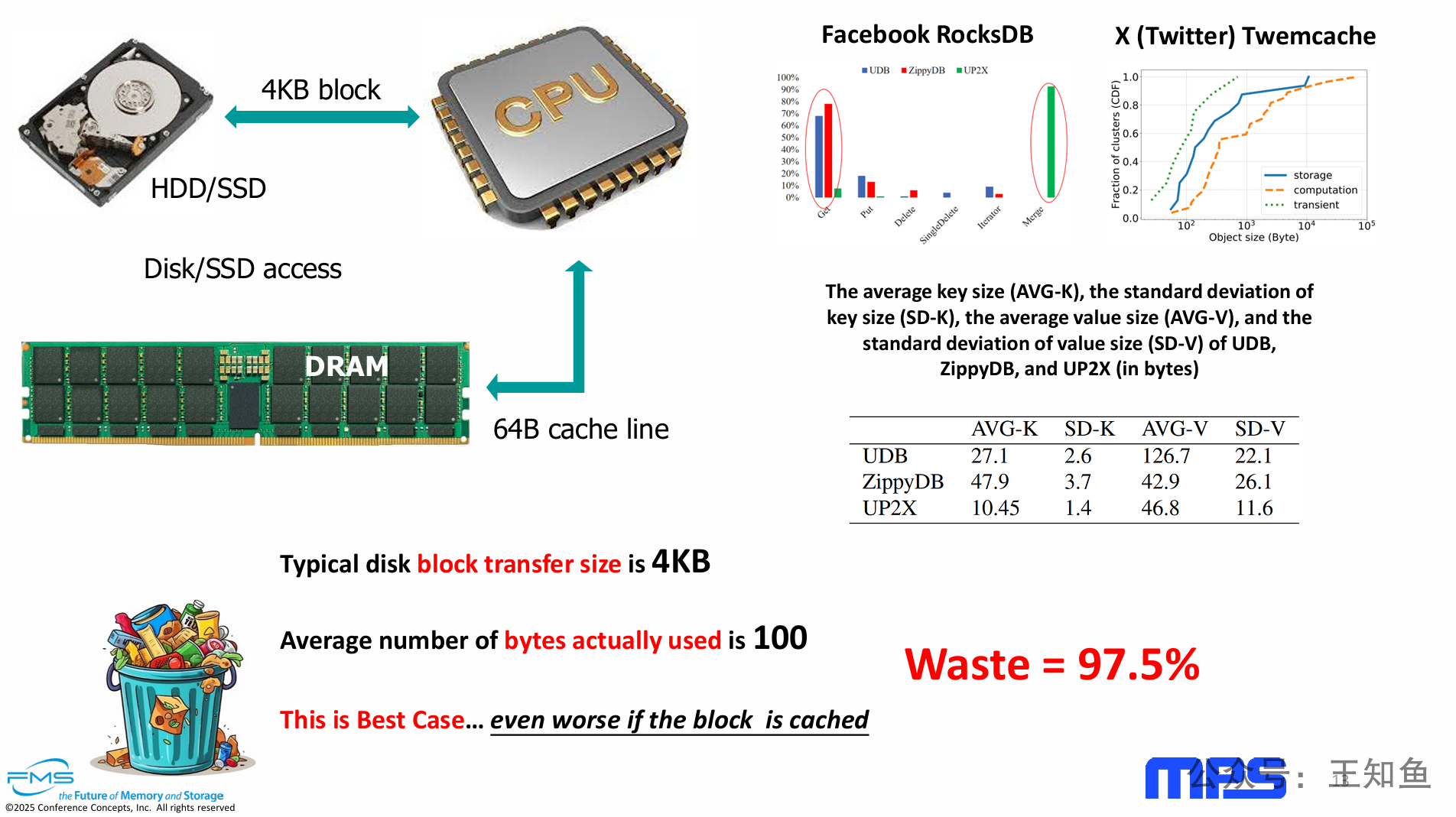
PPT的核心观点是,在存储I/O层面,标准的4KB块大小与现代应用中普遍存在的小数据对象(平均约100字节)之间存在巨大的粒度鸿沟,这导致了高达97.5%的I/O浪费,并且这种浪费会因缓存机制而被进一步放大。
-
存储I/O的粒度失配:问题的根源在于操作系统/文件系统定义的I/O单元(4KB)与应用程序实际需要的数据单元(~100字节)严重不匹配。
-
真实世界验证:这一论点并非凭空猜测,而是有来自Facebook和Twitter等大规模生产环境的真实数据作为强力支撑,证明了“小对象”是普遍现象。
-
双重资源浪费:这种失配不仅浪费了存储设备的I/O带宽和增加了延迟,当数据被读入内存缓存后,还会严重浪费宝贵的DRAM容量,造成“缓存污染”。
-
问题普遍性:至此,整个系列PPT已经完整地描绘了一幅“全链路浪费”的图景:从CPU寄存器、CPU缓存行、DRAM内部物理操作,一直到现在的存储I/O,数据访问的每一个环节都存在着严重的因粒度不匹配而导致的效率低下问题。

提出了一个旨在全面降低系统功耗的四点行动纲领。其核心思想是通过各种手段智能地、系统性地减少乃至消除不必要的数据移动。
这四个原则分别从四个层面给出了指导方向:
-
CPU微架构层面:精细化管理和评估CPU高级特性(如推测执行)的能效比。
-
系统软件与架构层面:强化数据局部性,优化数据在系统内部的流动路径,减少“跳数”。
-
计算范式层面:推动从“以计算为中心”向“以数据为中心”的革命性转变,发展计算存储等新技术。
-
行业标准与协议层面:从最底层重塑规则,开发新的硬件和通信协议,从根本上解决数据访问的粒度失配问题。
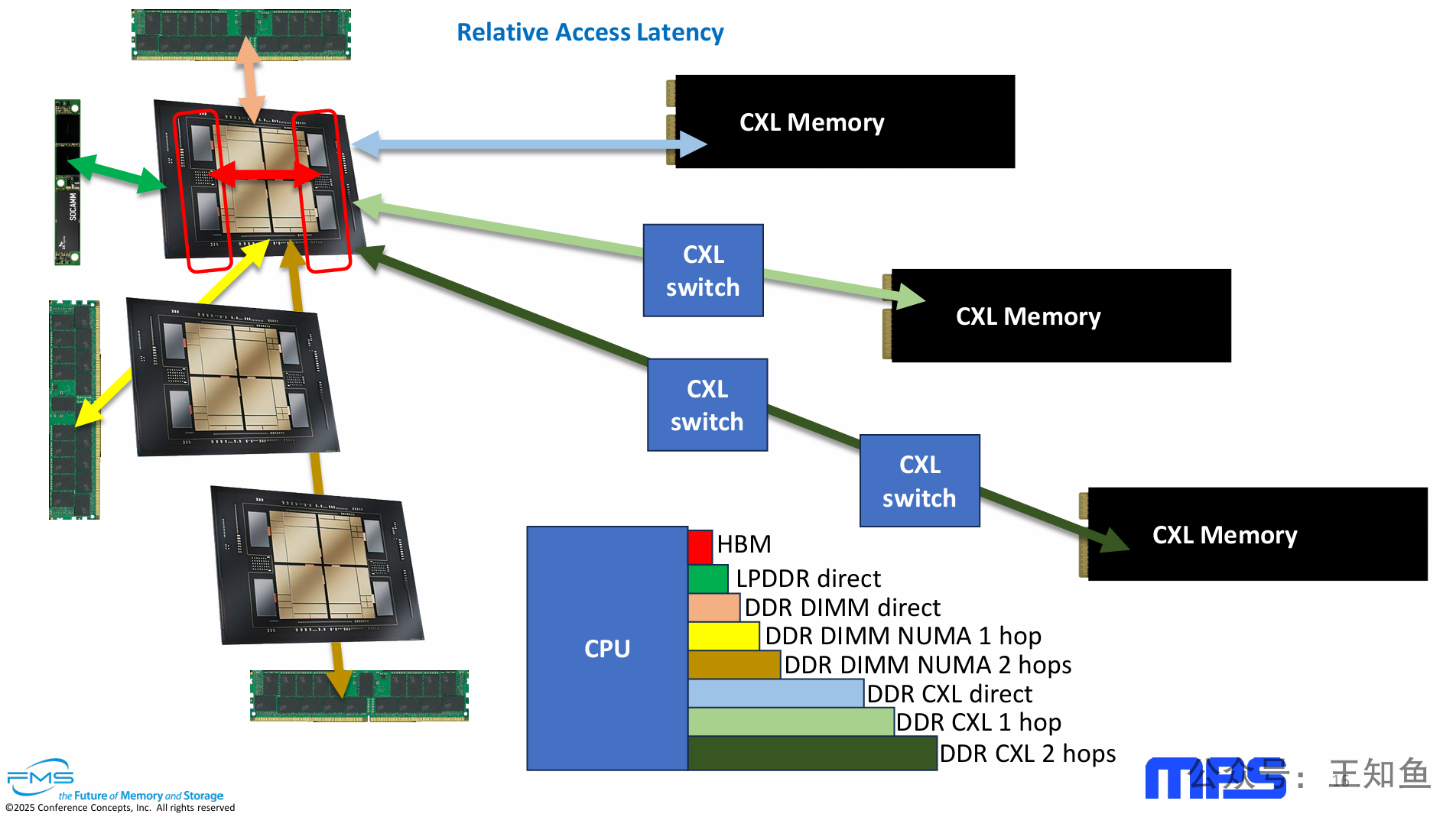
这张图 在很多分析材料中都有介绍,关于时延量级更详细的可参考之前整体的资料,这里截一张表格巩固对分级内存系统时延的认识。

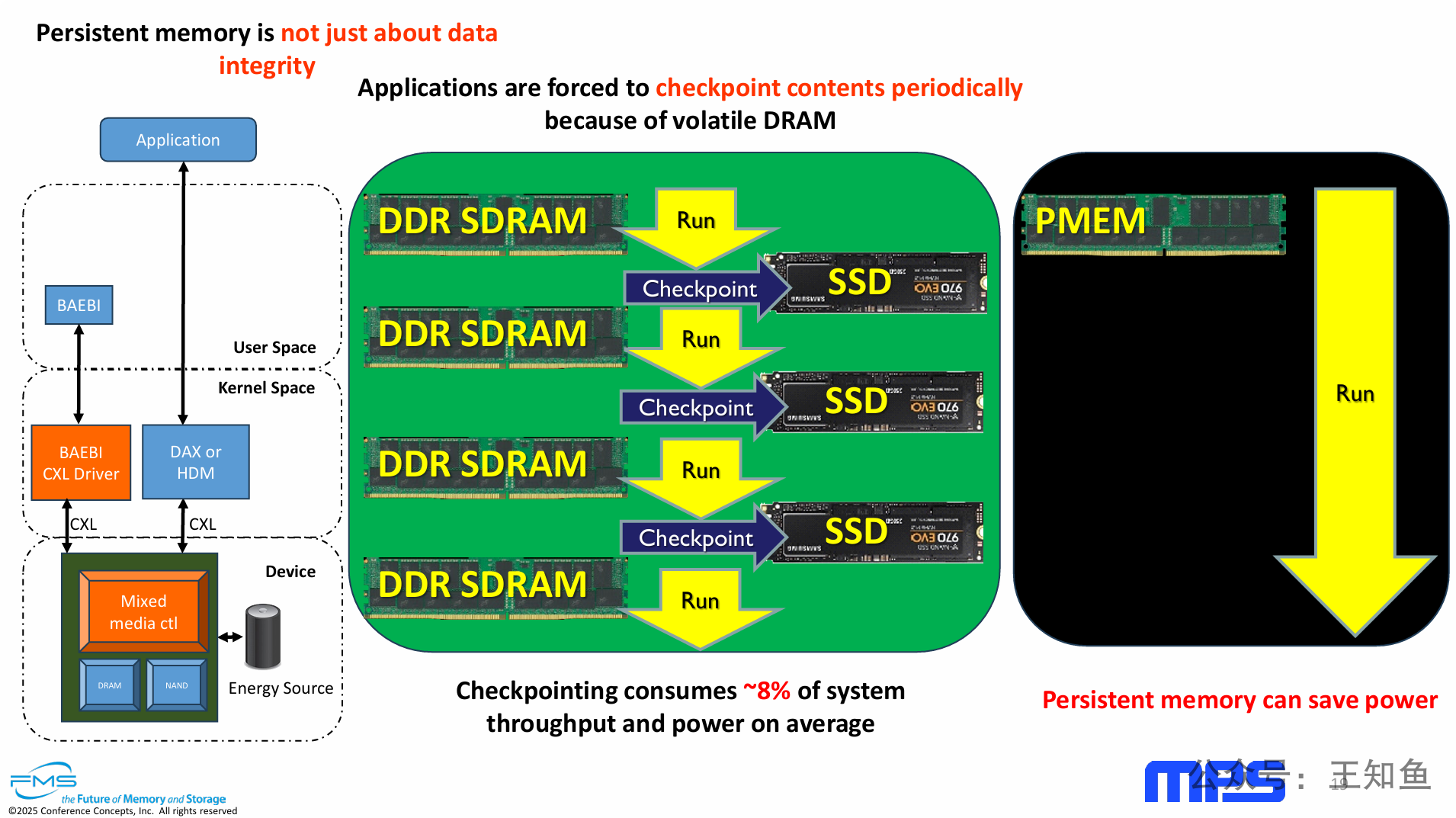
PPT的核心观点是,持久内存通过消除传统“DRAM + 存储”架构中因数据持久化需求而产生的“检查点”开销,为应用程序带来了显著的性能提升和功耗节省。
-
问题定义:传统依赖易失性DRAM的计算模型,其固有的“检查点”机制是系统效率(吞吐量和功耗)的一大开销(约浪费8%)。
-
解决方案:持久内存(PMEM)通过提供一个统一的、既能高速随机访问又具备非易失性的内存层,从根本上消除了执行检查点的必要性。
-
核心优势:PMEM的价值主张从被动的“数据保护”转向了主动的“性能提升”和“功耗优化”。它让应用得以不间断地运行,从而释放了被检查点占用的系统资源。
-
技术实现:这一变革由现代技术栈支撑,包括高速的CXL互联协议、DAX直接访问模式以及带有板载能源和智能控制器的混合介质硬件设备。
===
与易失性 DRAM 相比,持久性内存 在实际应用中需要考虑:
1. 数据持久性与一致性
-
数据持久性:需确保写入数据真正持久化,涉及CPU缓存刷新、乱序执行处理及显式刷新操作。
-
数据一致性:保证更新操作的原子性,特别是对于跨多个字的数据结构,需处理复杂的事务一致性。
2. 内存泄漏与错误处理
-
内存泄漏:PMEM中的内存泄漏具有持久性,系统重启无法清除,需在软件层面进行管理。
-
错误处理:应用程序可能需要直接处理来自PMEM介质的硬件错误,增加编程复杂度。
3. 编程模型与生态系统
-
编程模型:PMEM引入字节级访问,对数据结构设计和访问模式提出新要求,传统编程模型需调整。
-
软件生态系统:操作系统和应用程序对CXL内存(特别是PMEM)的感知和优化仍需加强,软件层(如操作系统、库、供应商解决方案)对于简化PMEM编程至关重要。
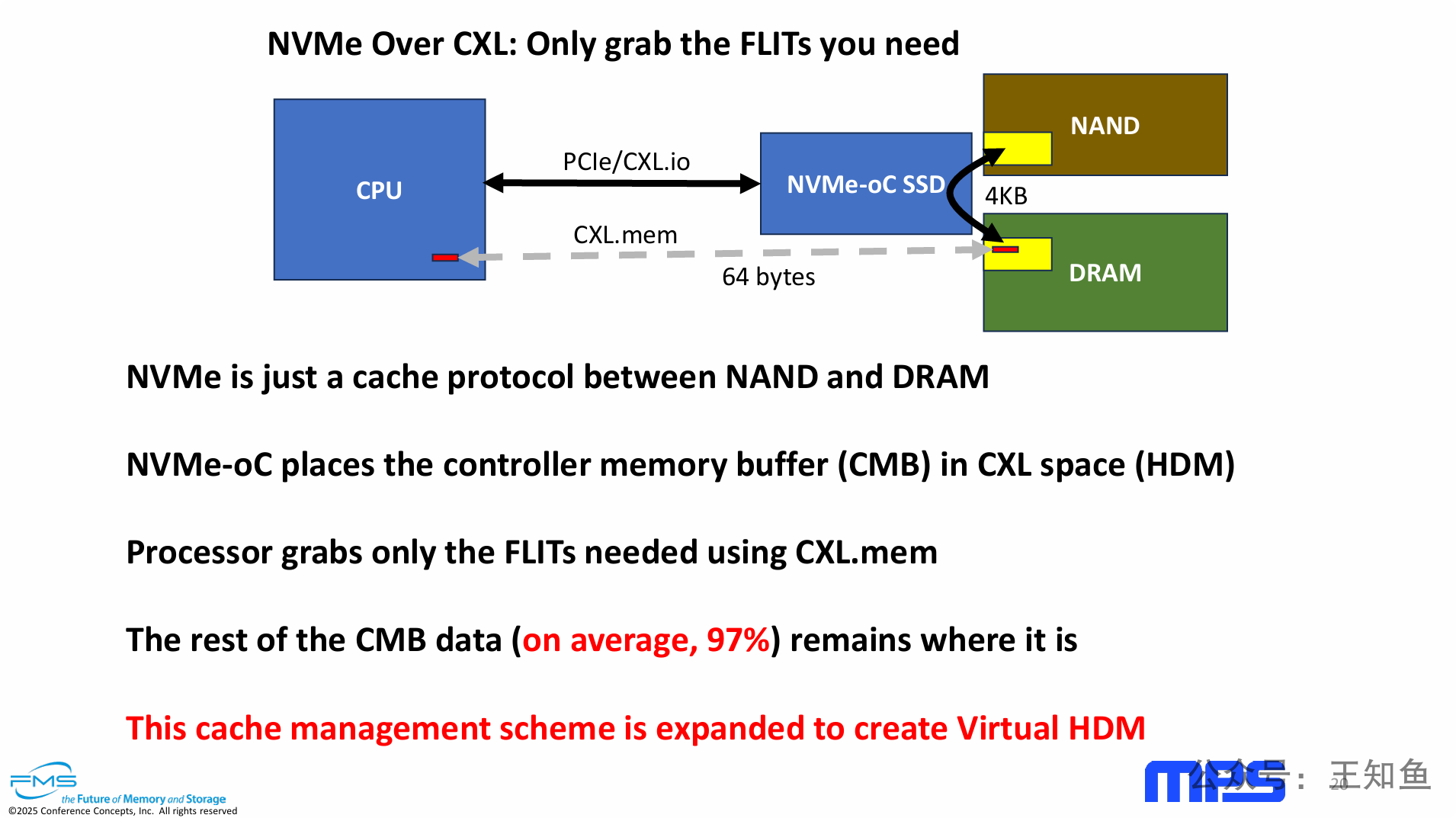
通过在CXL总线上运行NVMe协议(NVMe-oC),并利用CXL.mem的内存语义,可以实现对SSD内部数据缓冲区的细粒度访问,从而从根本上解决存储I/O中因“块尺寸”与“实际需求尺寸”不匹配而导致的巨大浪费。
-
解决方案:利用CXL技术,将SSD上的DRAM缓冲区(CMB)直接映射到CPU的内存地址空间。
-
核心机制:CPU不再通过传统的I/O命令传输整个4KB数据块,而是通过内存命令(
CXL.mem)直接以缓存行(64字节)的粒度,从SSD的缓冲区中“摘取”所需数据。 -
主要收益:该方法避免了将一个数据块中约97%的无用数据传输到主机内存,极大地节省了I/O带宽、降低了延迟,并显著减少了功耗。
-
技术演进:这不仅仅是一个孤立的优化,更是构建未来更先进的、虚拟化的、可组合内存架构(如Virtual HDM)的关键基石。
这也是为什么越来越多的SSD存储厂商在强调内存语义,在语义(元数据)的加持下,上层业务系统能更高效的搜索、调用SSD上的原始数据,从而实现数据的精准提取,最终实现更高的能效比。
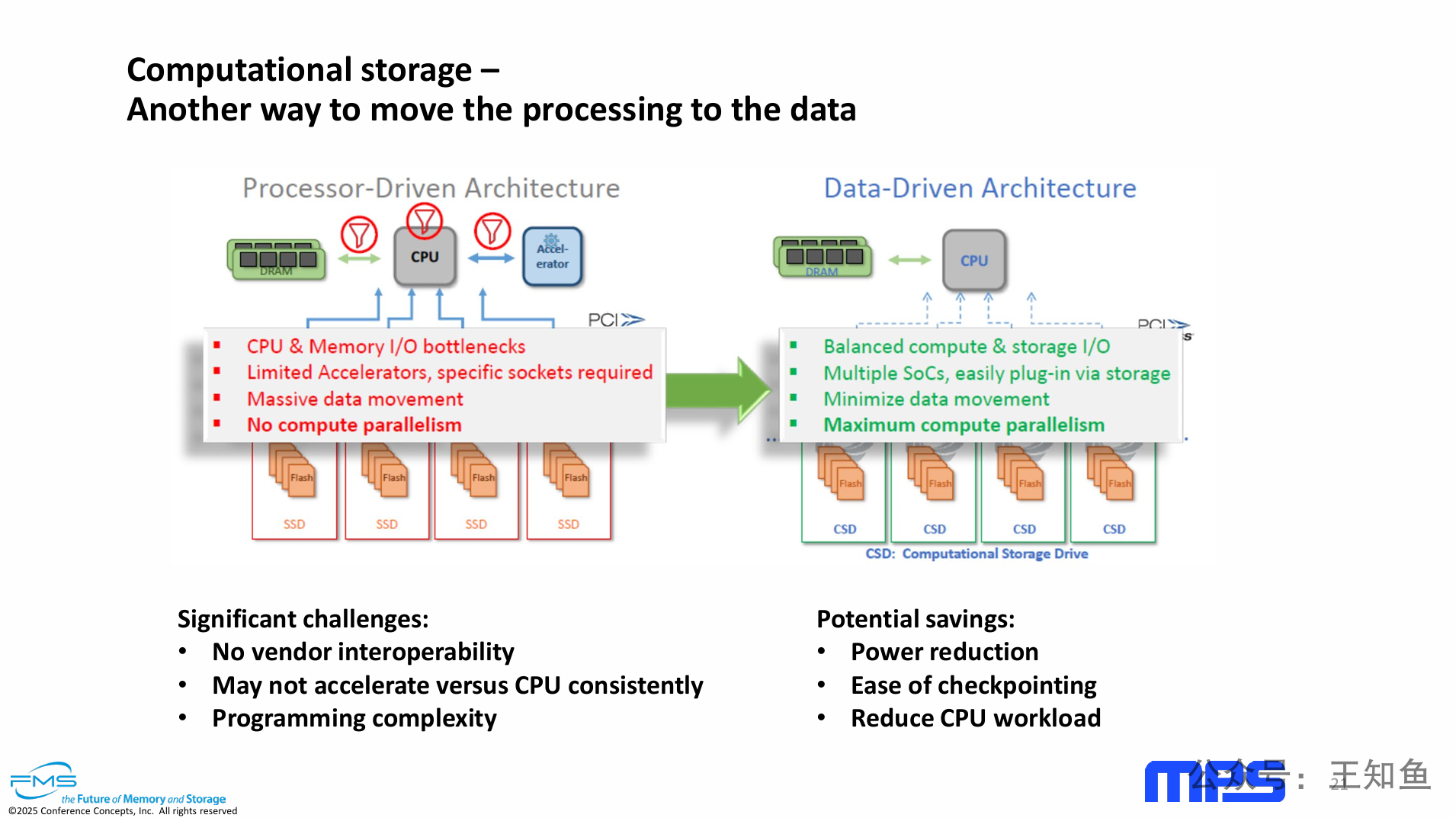
计算存储通过将计算能力下推到存储设备内部,将传统“处理器驱动”的集中式架构,转变为“数据驱动”的分布式架构,从而根本性地解决了海量数据移动带来的瓶颈和功耗问题。
-
范式转变:计算存储是一种架构上的革新,其本质是“让数据在哪里,计算就在哪里发生”,颠覆了数据必须围绕CPU移动的传统模式。
-
核心优势:通过在存储设备端并行处理数据,计算存储可以有效解决I/O瓶颈,最大限度减少数据移动,从而显著降低功耗、减轻CPU负载,并提供一个易于扩展的并行计算平台。
-
现实挑战:尽管前景广阔,但计算存储作为一项新兴技术,目前仍面临三大挑战:标准化(互操作性)、普适性(性能一致性)和易用性(编程复杂性)。
-
价值主张:这张PPT有力地论证了计算存储是实现前几页所提出的“降低功耗”、“减少浪费”等目标的关键技术路径之一。