
AI 双子星:英伟达(Nvidia)和博通(Broadcom)的补位优势
问题意识
在AI浪潮席卷全球的今天,英伟达(Nvidia)和博通(Broadcom)无疑是半导体领域的两大巨头。市场普遍认为,它们在AI数据中心的主导地位上存在零和博弈,但事实果真如此吗?本文将深入剖析这两家公司截然不同的战略路径:英伟达构建了垂直整合的AI计算平台,掌控“AI工厂”的核心引擎;而博通则围绕连接性、定制芯片和高利润软件,打造了持久的特许经营模式。它们是竞争对手,还是互补共生的伙伴?在互联网诞生以来最重要的技术周期中,这两家公司如何开辟出独特的互补地位,共同推动AI时代的发展?

深度分析 作者:Dave Vellante
我们认为,目前普遍认为博通公司(Broadcom Inc.)和英伟达公司(Nvidia Corp.)在人工智能数据中心主导地位上陷入零和博弈的说法具有误导性。现实情况是,这两家公司正在玩截然不同的游戏。
英伟达构建了一个垂直整合的计算和软件平台,该平台已成为AI工厂时代的核心引擎。相比之下,博通则围绕连接性、定制芯片和高利润软件构建了一个持久的商业模式。这些策略有所重叠,但并非相互排斥。我们认为,真正值得关注的是,自互联网诞生以来最重要的技术周期中,这两家公司是如何开辟互补地位的。
在本期深度分析中,我们将探讨博通和英伟达的不同策略,并解释为什么一家公司的成功不一定会稀释另一家公司的前景。
英伟达的平台策略:掌控AI工厂
英伟达的策略概念上直截了当,但复制起来异常困难。该公司构建了一个从图形处理器(GPU)开始并延伸至整个系统的全栈平台。黄仁勋(Jensen Huang)反复强调,竞争单位不再是芯片,而是系统,或者英伟达所称的“AI工厂”。英伟达已将自己定位为任何希望建立这些工厂的不可或缺的供应商。
英伟达堆栈的核心是 Hopper 和 Blackwell 等 GPU,它们与 NVLink/NVSwitch 互连,形成紧密耦合的计算域。这些“计算舱”(pods)可扩展至72个GPU,创建高带宽、低延迟的“孤岛”,针对AI训练等极致并行处理工作负载进行了优化。
英伟达通过 InfiniBand 将这些计算舱向外扩展,InfiniBand 是其通过收购 Mellanox 获得的专有网络技术。此外,英伟达还利用其 Spectrum-X 以太网,这是一种专为确定性处理AI流量而设计的以太网结构。
硬件之上是其 CUDA 软件栈和数百个库,它们是使这些系统可编程且高度优化的软件粘合剂。英伟达的软件护城河很深,数万名开发者被锁定在其生态系统中,并且支持几乎无限多的用例。
此外,该公司还提供 DGX、NIMS 推理微服务以及用于模拟和数字孪生的 Omniverse 等系统和服务,进一步巩固了其作为平台而非仅仅芯片供应商的地位。
创新节奏永不停歇。每年,英伟达都会推出新的架构,提供更高的每瓦性能和更高的集群利用率。这种年度节奏将资本支出转化为经常性盈利周期。结果是,当功耗成为限制因素且系统利用率不足时,客户会花费更多,每瓦生成更多令牌,并规模化降低单位成本。
博通的特许经营模式:持久、开放、盈利
博通的方法与英伟达截然不同。首席执行官 Hock Tan 和博通半导体解决方案事业部总裁 Charlie Kawwas 并没有追逐 GPU 或构建巨型AI系统。相反,博通的策略是识别持久特许经营权——拥有十年或更长发展空间的市场——建立技术领先地位,并以严格的运营纪律来管理它们。
一些投资者因博通是“商品化参与者”而避开它。在我们看来,这种说法具有误导性,并且缺乏对博通生产的产品(包括其无线产品组合)所需的工程投资的理解。
在半导体领域,博通在连接性方面占据了主导地位。其 Tomahawk 和 Jericho 系列主导着商用以太网交换市场。它还赢得了谷歌、Meta 以及很可能是字节跳动的定制芯片设计订单,使博通深入融入超大规模AI建设。这些是数十亿美元、长期且极具战略意义的交易。该公司刚刚宣布又完成了一笔100亿美元的定制芯片交易,据广泛报道是与 OpenAI 达成的,OpenAI 像超大规模厂商一样,正在设计自己的芯片以减少对英伟达的依赖。
在最近的财报电话会议上,Tan 有一个看似无意但却具有讽刺意味的“泄露”,他说了以下内容:
今天的AI机架仅能以每秒28.8太比特的带宽,使用专有 NVLink 扩展72个GPU。另一方面,今年早些时候,我们与 OpenAI —— 抱歉,是 开放以太网 —— 推出了 Tomahawk 5,它可以为使用 XPU 的客户扩展512个计算节点。
这个口误发生在他宣布最近的100亿美元定制芯片交易之后,这让包括我们在内的许多观察家得出结论,OpenAI 显然(以一种好的方式)牢牢占据了 Tan 的思维空间。
Charlie Kawwas 的口头禅是“OSP”。它代表开放(open)、可扩展(scalable)、高能效(power-efficient),并构成了博通的理念。该公司认为,以太网和 PCIe 等开放标准最终将胜过 InfiniBand 和 NVLink 等专有方法。历史表明这是一个不错的赌注,这也是英伟达也拥抱以太网的原因。
在软件方面,博通围绕 VMware Cloud Foundation 重塑了 VMware,宣布推出 VCF 9.0,声称通过数千名工程师的努力,实现了所有这些不同的 VMware 软件模块的集成。博通迫使客户签订更高价值合同的策略,尽管存在争议,但已将运营利润率推高至70%以上,毛利率超过90%,远超其他软件即服务(SaaS)的毛利率。此外,在我们看来,VMware 已成为最强大的本地部署公共云替代方案,并代表了市场上最成熟的私有云产品。
博通 VMware 策略的“怪癖”在于,Hyper-V、Nutanix、Red Hat 等替代方案获得了发展势头,而此前它们在虚拟化竞争中被排除在外。博通不想要那些不愿为完整的 VCF 堆栈支付高价的客户,但那些盈利能力远不及博通的替代厂商乐于接受这些业务。
VMware 误导性的客户支出概况
下图显示了企业技术研究公司(Enterprise Technology Research)针对虚拟化市场的净得分(Net Score)方法。纵轴(净得分)代表在每个平台上增加支出的客户净百分比,横轴显示在数据集中的渗透率。这些数据可能会让人认为 VMware 正在苦苦挣扎,因为它从2023年1月开始急剧下降。但该方法未能捕捉支出金额。因此,它忽略了博通的策略是更集中地关注那些愿意为整个 VCF 捆绑包付费以降低总拥有成本的高价值客户。
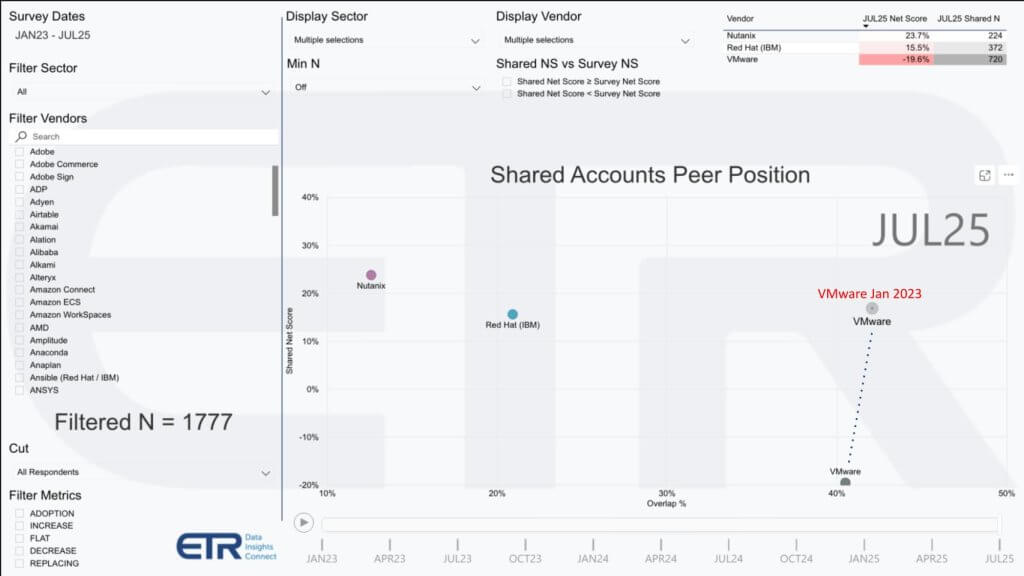
这是经典的博通策略。它只在能够主导的市场竞争。就 VMware 而言,重要的不是客户数量,而是那些愿意接受价格上涨并购买完整捆绑包的客户数量。与许多误导性说法相反,博通大力投资工程研发,并用关键技术围绕其平台,从而带来明确的投资回报。这就是为什么(例如)即使是英伟达也从博通购买网络技术。
底线是,博通无需在 GPU 方面与英伟达正面竞争也能蓬勃发展。相反,它提供“粘合剂”——SerDes(信号中继放大器)、网卡(NIC)、光模块和交换机——使大型AI系统成为可能。用 Kawwas 的话来说,博通不制造 GPU,它制造的是让 XPU 和 HBM 工作的“东西”。此外,它还获得了数十亿美元的长期合同,为包括谷歌、Meta、字节跳动以及现在的 OpenAI 在内的一些世界顶级公司构建定制AI芯片。
规模与性能:技术权衡
两家公司之间的一个主要争议点是规模问题。在博通最近的财报电话会议上,Tan 将英伟达的 NVLink 72 定位为“仅能以每秒28.8太比特的带宽扩展72个GPU”,并将其与博通能够使用 Tomahawk 5 连接512个节点的以太网结构进行对比。表面上看,这使得英伟达的方法显得有限。但在我们看来,这种比较具有误导性。
我们对英伟达使用“纵向扩展(scale up)、横向扩展(scale out)、跨越扩展(scale across)”术语的解释如下:
- 纵向扩展(Scale-up) = 单个机架中紧密耦合的节点 (NVLink/NVSwitch)。
- 横向扩展(Scale-out) = 跨机架集群 (InfiniBand/Ethernet)。
- 跨越扩展(Scale-across) = 跨数据中心。
在 Tan 的评论中,博通似乎更宽松地使用了“纵向扩展”,意指“支持比72个GPU更大的集群”。但从技术上讲,用以太网连接512个计算节点是横向扩展结构,而非纵向扩展。特别是,纵向扩展通常被认为是,通过紧密耦合组件来使_单一逻辑系统_变得更大。可以想象单个盒子中的对称多处理。
在我们看来,Tan 将 NVLink 的机架级“孤岛”(72个GPU)描述为小规模,并将其与博通基于以太网连接数百个节点的能力进行对比。在此过程中,他随意使用了术语,将以太网的集群扩展称为“纵向扩展”,而实际上在经典术语中,这属于横向扩展。
相比之下,英伟达的72个GPU指的是一个紧密耦合的 NVLink 域,其中高带宽内存池在 GPU 之间共享,从而实现高效的并行操作。博通的512个节点实际上指的是以太网结构的横向扩展能力。这不是“苹果对苹果”的比较。这两种方法解决的是不同的问题。NVLink 最大化机架内的性能,而以太网则将集群扩展到跨机架和跨行。
权衡在于,NVLink 提供每个 GPU 的峰值性能,而以太网提供整体级别的可扩展性和经济性。在实践中,运营商会同时使用两者——NVLink 用于高性能计算“孤岛”,以太网用于将这些“孤岛”连接起来。
财务状况:两者皆卓越
英伟达和博通的财务模型突显了他们不同的策略。表面上看,两家公司都发布了非凡的业绩,但实现方式却不同。
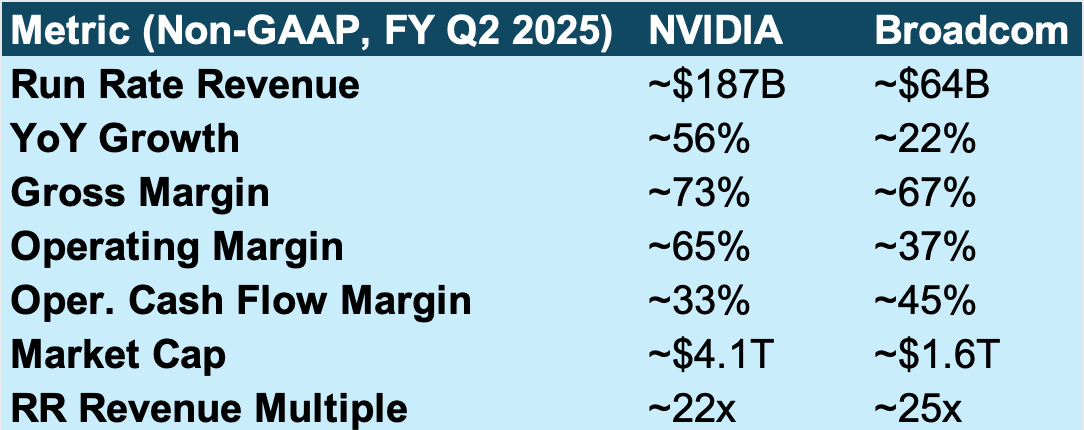
英伟达 目前的年收入约为 1870亿美元,同比增长 56%,令人印象深刻。尽管从前几个季度的三位数增长率有所放缓,但这仍然是任何超大市值公司中最快的增长态势之一。利润率同样令人印象深刻:73%的毛利率、65%的运营利润率 和 33%的运营现金流。凭借超过 4万亿美元 的市值和 22倍的年化收入倍数,英伟达被估值为一代人难遇的成长型公司,而非传统的半导体供应商。
在我们看来,这反映了投资者坚信英伟达的全栈AI工厂策略仍有数年发展空间,年度节奏升级、CUDA 软件锁定以及超大规模厂商需求弹性维持着增长势头。当功耗是限制因素,并且通过快速技术更新可以实现利用率/效率提升时,其经济价值主张具有吸引力。
在最近的财报电话会议上,英伟达强调了 Blackwell 的推广,NVLink 72 部署在推理工作负载上比 Hopper 展现出10倍的效率提升。管理层强调,推理现在与训练一样,成为重要的收入来源。在投资回报率方面,弹性(杰文斯悖论)使得英伟达能够在降低每个令牌价格的同时仍能实现收入增长。
相比之下,博通 以不同的策略取得了卓越的成果。该公司目前的年化收入运行率约为 640亿美元,同比增长 22%,稳健但更具衡量性。上个季度,其非AI半导体产品是逆风,但预计将环比增长。博通67%的毛利率低于英伟达,但博通在现金生成方面表现出色,运营现金流利润率高达 45%——考虑到业务规模,这是一个了不起的数字。运营利润率为 37%,远低于英伟达,但与博通半导体和基础设施软件的组合相符。
其估值,约 1.6万亿美元 市值和 25倍的收入倍数,引人注目。投资者开始关注博通,不是因为其超高速增长,而是因为其持久性、纪律性和战略定位——作为AI基础设施的连接组织、定制AI芯片的首选公司以及其 VMware 资产的价值创造者。
博通最近的财报强调了 Tomahawk 5 能够将集群扩展到远超 NVLink 计算舱的规模。我们注意到 Tan 声明中的注意事项,如前所述。Tan 重申 VMware Cloud Foundation 的采用进度超前,软件利润率接近70%。AI芯片年化收入达到约160亿美元,得益于超大规模定制芯片订单和一笔据广泛报道与 OpenAI 达成的100亿美元激动人心的交易。
在我们看来,这些财务指标突显了英伟达是一家以其高速增长而获得溢价的超增长平台公司,而博通则是一家因其一致性、现金流和长期特许经营权而受到重视的持久复合增长公司。两种模式都非常出色,两家公司都对AI运动至关重要,但它们反映了在AI时代如何获取价值的截然不同的理念。
市场和投资者影响
我们认为这些策略的意义重大,体现在:
- 这不是零和博弈。 两家公司都可以蓬勃发展。英伟达主导加速计算,博通主导连接性和软件变现,与AI时代一些最大、最重要的平台建立了高价值的长期合作关系。
- 系统是竞争单位。 效率的关键在于每瓦性能和利用率。英伟达在计算舱内部推动这些,博通则在结构之间推动。尽管两家公司都拥抱标准,但英伟达围绕芯片、软件、库、完整系统和生态系统构建了专有护城河。博通则利用开放生态系统,其护城河是工程和技术领导力,用于创造难以开发但对完整系统运行至关重要的产品。
- 风险概况。 英伟达面临需求弹性、超大规模厂商内部化/风险敞口、供应限制和公共政策逆风(特别是中国市场)。博通面临与AI相关的类似需求风险,平衡 VMware 利润目标与客户反弹,以及高度集中的定制芯片客户。
- 投资者视角。 英伟达作为超增长动量股进行交易。博通作为具有高利润率特征的持久复合增长股进行交易。两家公司相对于大盘都溢价交易,但鉴于其盈利能力和增长率,投资者已经奖励了两家公司,只要AI势头持续,就会继续这样做。
结论
在我们看来,市场不应再将博通和英伟达视为零和竞争中的对手。此外,一些专家认为博通是商品化竞争者的观点,在我们看来是荒谬的。英伟达和博通正在玩不同的游戏,而这两者对AI时代都至关重要。英伟达构建驱动新工作负载的计算引擎和软件平台。博通则确保这些引擎能够在十年内实现扩展、互连并盈利运营。
我们的研究表明,随着AI从云端走向企业,再走向现实世界系统,英伟达和博通都将以截然不同但高度协同的方式扩展其护城河。真正的战斗不在它们之间,而在于这种新架构与它正在取代的传统计算堆栈之间。